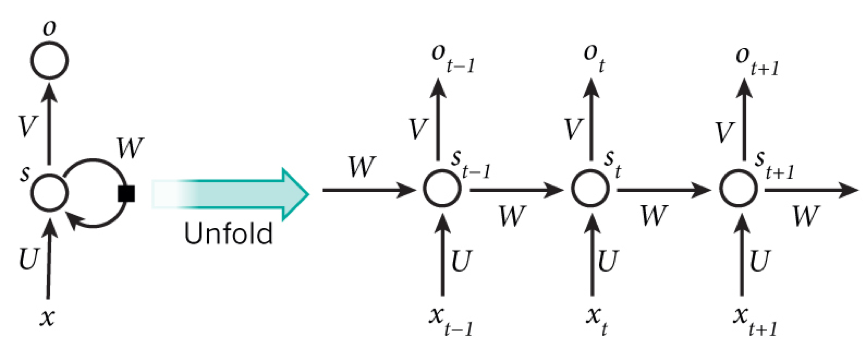
概述:机器学习和大数据技术在信贷风控场景中的应用(2)
1.基于知识图谱技术的复杂网络
在影视节目当中,我们经常看到警察办案时会把嫌疑人、证人、受害人及他们之间的关联关系等信息画在墙上,用以分析案情,这就是典型的关系图谱应用。墙上的画便是图,图中有用的信息便是知识,将其进一步扩展到其他事物;人为实体,在图中我们称之为点,人之间代表着关联关系的连线,在图中我们称之为边,就这样点与边共同组成了我们的关系图谱。

构建关系图谱的底层还是大数据的技术:基于庞大的用户数据,从不同的数据源抽取出来存入到图数据库里,所以数据是构建关系图谱的基础。一种是以关系型数据库存储的结构化数据,例如:IP地址,经纬度,设备指纹等,另一种是爬虫采集的非机构化数据,例如行为记录、网上的浏览记录。实践应用中我们利用机器学习、自然语言处理技术把这些数据变成结构化的数据也存入到图谱里。
从用户大数据和基于大数据的关系图谱体系我们可以实现以下目的:
2.1 资料伪造识别
校验用户信息可以用来判断借款人是否可能存在欺诈风险,使用关系图谱做交叉校验,虽然不能保证百分之百的准确性,但是它在人工审核时便是一个有力的参考依据。欺诈用户填写的个人信息通常都是虚假的。例如:比如借款人张三和借款人李四填写的是同一个公司电话,但张三填写的公司和李四填写的公司完全不一样,这就成了一个风险点。我们将关系图谱数据可视化,可以很直观的发现两者的矛盾,我们便可以判断他们二人至少有一人存在欺诈风险。
2.2 团伙欺诈分析
在信贷场景中,团伙欺诈造成的损失更加严重,不过从繁复的数据中发现团伙的难度也很大。基于知识图谱我们通常直观分析多层级的数据,一度关联、二度关联、三度关联,甚至是更多维度关联。团伙虽然使用虚假信息进行授信、支用,但通常都有共有的信息,例如同一个WIFI,同一片区域。LOUVAIN、LPA、SLPA等社区发现算法、标签传播算法可以有效快速的发现团伙。

2.3 失联客户管理
对于贷后管理来说,用户本人及紧急联系人失联是催收失败最大的原因,这时可以利用关系图谱去发现失联用户的潜在联系人,提高催收成功率。例如张三是失联用户,李四和赵六是张三的联系人也都失联了,这时我们可以试图通过李四的联系人王五,或者与张三使用相同设备的用户老王来达到失联客户管理的目的。

3.征信数据与信用评分卡
3.1征信与大数据
与国外相比,中国最大的差异在于征信体系的不完善。我们的人行征信系统覆盖了8亿人,但是可能只有4亿左右是有信贷记录的,剩下的无任何信贷记录的,我们称之为白户。所以国内****对于大部分非中高端用户实际上是不愿意也没有能力提供金融服务的。没有征信数据,那套国外搬过来的基于征信数据的方式方法就不管用了。
不过,我们很快发现,利用互联网技术可以解决征信数据缺失的白户问题,而这些看似与信贷记录不相关的数据在一定程度上却能够评估是否能够给该用户借款:
(1)All data is credit data:互联网可以提供每个信贷申请用户庞大的、碎片化的、种类繁多的信息。这里面包括用户提交的电子化信息(如身份证、营业执照、房产证、学历证、工资单、社保,****流水等),第三方权威机构的查询信息(如公民身份证查询中心、教育部学历中心、法院诉讼信息查询中心等可查询信息),还包括了海量的互联网碎片数据,如用户的电商交易信息、微博等社交网络数据,百度搜索引擎数据等。
(2)互联网的高效性和便捷性使我们能以较低的成本、较短的时间,积累大量的用户数据,为分析建模提供足够的样本量。
在信贷的业务实践中,常用的行业大数据包括:
央行征信报告:一般持牌金融机构有央行征信介入权限,包括个人的执业资格记录、行政奖励和处罚记录、法院诉讼和强制执行记录、欠税记录等。
司法信息:最高法以及省市各级法院的最新公布名单,包括执行法院、立案时间、执行案号、执行标的、案件状态、执行依据、执行机构、生效法律文书确定的义务、被执行人的履行情况、失信被执行人的行为等信息。
公安信息:覆盖公安系统涉案、在逃和有案底人员信息,包括案发时间、案件详情如诈骗案/生产、销售假****案等信息。
****信息:****储蓄卡/****支出、收入、逾期等信息。
航旅信息:包含过去一年中,每个季度的飞行城市、飞行次数、座位层次等数据。
社交信息:包含社交账号匹配类型、社交账号性别、社交账号粉丝数等。
运营商信息:核查运营商账户在网时长、在网状态、消费档次、通话习惯等信息。
网贷黑名单:根据个人姓名和身份证号码验证是否有网贷逾期、黑名单信息。
驾驶证状态,租车黑名单,电商消费记录等也是可以考量的因素
正是因为大数据技术的发展才形成了带着强烈中国特色的官方+民间结合的征信体系,支撑互联网信贷脱离蛮荒可以实现高速发展,信贷从业者可以在合规的前提下获取对提升效率有用的用户信息完善风控策略。
3.2 机器学习与评分卡
评分卡我们应该是最为熟悉的,芝麻信用分就是一个典型的信用评分,支付宝官方利用自身积累及外部征信渠道获取的各种数据从五个维度对一个用户进行评分,而这个评分对于每个用户来说是透明的,这也非常好帮助用户理解和改善自身的信用状况。
从和信贷业内的小伙伴沟通来看,芝麻的信用评分还是比较有区分度的,这与阿里的大数据积累息息相关,阿里体系内积累了大量用户特有数据可以对用户形象进行更好的刻画。

这套评分卡的背后其实是一套依赖在大数据基础上的机器学习算法,因此在本身拥有大量数据的基础上如何挖掘出一套有效的客户评分这就是机器学习需要做的事情。
机器学习中目前应用最广泛的就是有监督学习:这类模型最复杂的地方在于模型的训练过程,算法人员根据这些历史用户的表现打上标签(逾期/不逾期),基于这些用户大量数据,使用不同的算法(一般来说都会使用逻辑回归算法)来对这些用户进行评分,得到一个在各维度评价指标来看都能过关的模型,并用这个模型来预测未来的数据表现。

目前********体系、网贷体系基本都是使用类似的方法构建评分卡,当然不同的场景、不同的行业所用的评分卡也不尽相同。基于这套评分卡我们基本上可以在用户申请环节实现量化风险的目的。基于大数据的机器学习并不是完全改变传统风控,实际是丰富传统风控的数据纬度和量化风险的方式。
结语
本文简单介绍了大数据和机器学习在信贷风控领域的应用场景。机器学习听起来很高大上,在实际工作中也经常会遇到一味炒作概念的人,过分夸大机器学习所能起到的作用,或者盲目的追求高深复杂的算法。不过无论是机器学习还是大数据其本质还是为了服务业务,提高业务的效率降低成本是其最根本的目的。
随着信贷行业的不断发展,机器学习和大数据技术的越来越成熟,二者结合的应用场景相信也会愈加丰富,相信在这块未来会有更多新颖的应用场景。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。