Python数据可视化:类别比较图表可视化
在学习本篇博文之前请先看一看之前发过的关联知识:
Python数据可视化:如何选择合适的图表可视化?
根据表达数据的侧重内容点,将图表类型分为6大类:类别比较图表、数据关系图表、数据分布图表、时间序列图表、局部整体图表和地理空间图表(有些图表也可以归类于两种或多种图表类型)。
本篇将介绍类别比较图表的可视化方法。
类别比较型图表的数据一般分为:数值型和类别型两种数据类型,主要包括:柱形图、条形图、雷达图、词云图等,通常用来比较数据的规模。如下所示:

1
柱状图
柱形图是一种以长方形的长度为变量的统计图表。柱形图用于显示一段时间内的数据变化或显示各项之间的比较情况。
在柱形图中,类别型或序数型变量映射到横轴的位置,数值型变量映射到矩形的高度。控制柱形图的两个重要参数是:“系列重叠"和“分类间距”。
“分类间距"控制同一数据系列的柱形宽度;
“系列重叠"控制不同数据系列之间的距离。
下图为常见的柱形图类型:单数据系列柱形图、多数据系列柱形图、堆积柱形图和百分比堆积柱形图。
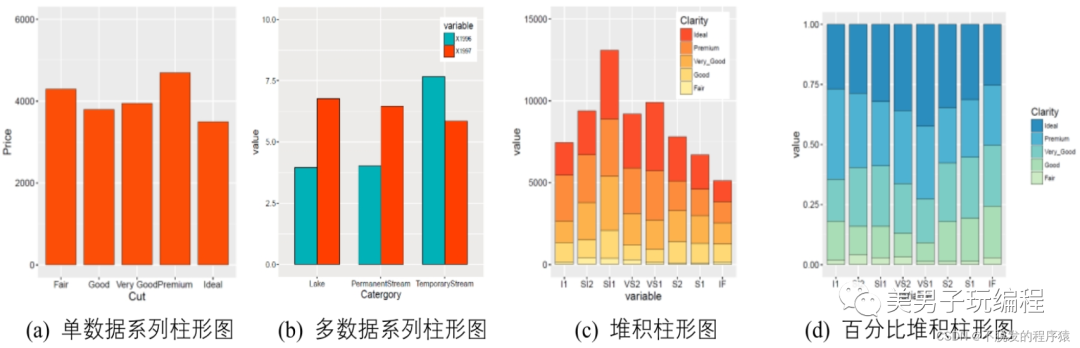
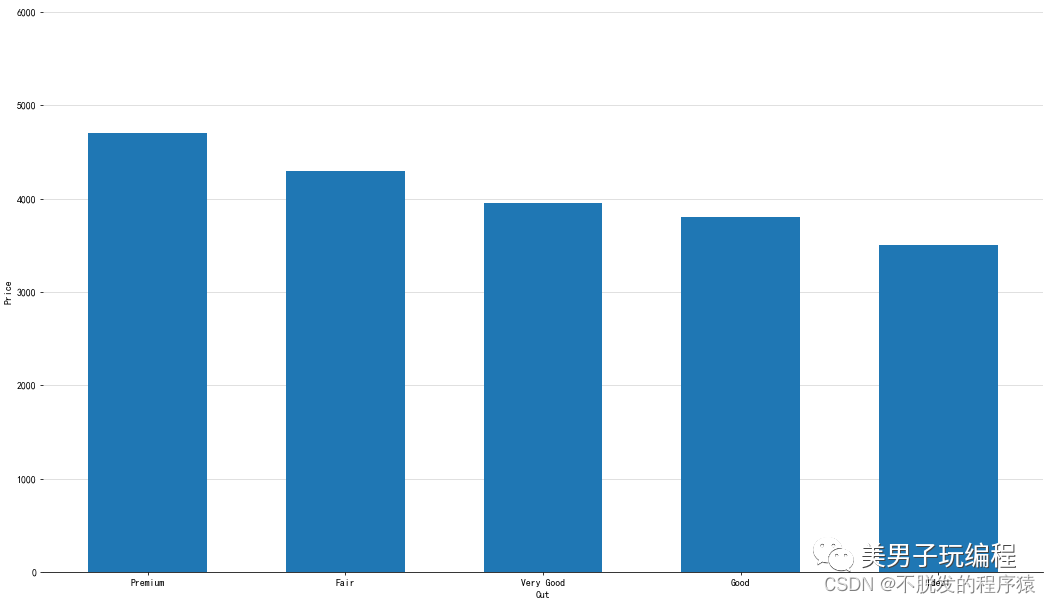
1.1、单数据系列柱形图
通过一个示例了解单数据系列柱形图的使用,实现代码如下所示:
mydata = pd.DataFrame({'Cut': ["Fair", "Good", "Very Good", "Premium", "Ideal"], 'Price': [4300, 3800, 3950, 4700, 3500]})
Sort_data = mydata.sort_values(by='Price', ascending=False)
fig = plt.figure(figsize=(6, 7), dpi=70)plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1)plt.grid(axis="y", c=(217/256, 217/256, 217/256)) # 设置网格线# 将网格线置于底层ax = plt.gca() # 获取边框ax.spines['top'].set_color('none') # 设置上‘脊梁’为红色ax.spines['right'].set_color('none') # 设置上‘脊梁’为无色ax.spines['left'].set_color('none') # 设置上‘脊梁’为无色
plt.bar(Sort_data['Cut'], Sort_data['Price'], width=0.6, align="center", label="Cut")
plt.ylim(0, 6000) # 设定x轴范围plt.xlabel('Cut')plt.ylabel('Price')plt.show()效果如下所示:
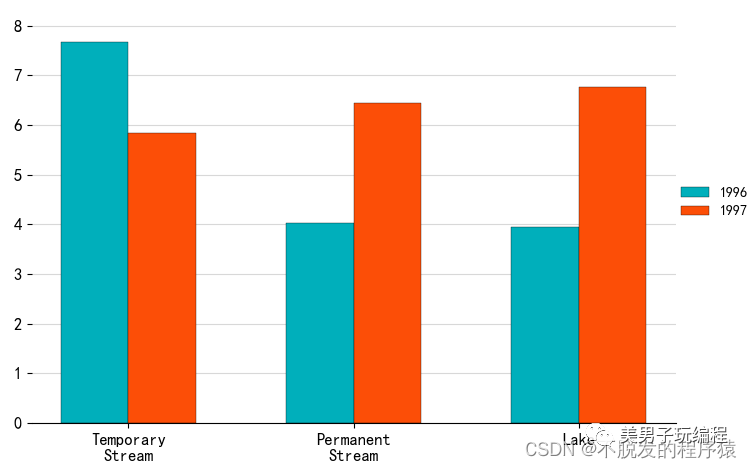
1.2、多数据系列柱形图
通过一个示例了解多数据系列柱形图的使用,实现代码如下所示:
x_label = np.array(df["Catergory"])x = np.arange(len(x_label))y1 = np.array(df["1996"])y2 = np.array(df["1997"])
fig = plt.figure(figsize=(5, 5))plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1) # 设置绘图区域大小位置
plt.bar(x, y1, width=0.3, color='#00AFBB', label='1996', edgecolor='k', linewidth=0.25) # 调整y1轴位置,颜色,label为图例名称,与下方legend结合使用plt.bar(x+0.3, y2, width=0.3, color='#FC4E07', label='1997', edgecolor='k', linewidth=0.25) # 调整y2轴位置,颜色,label为图例名称,与下方legend结合使用plt.xticks(x+0.15, x_label, size=12) # 设置x轴刻度,位置,大小
# 显示图例,loc图例显示位置(可以用坐标方法显示),ncol图例显示几列,默认为1列,frameon设置图形边框plt.legend(loc=(1, 0.5), ncol=1, frameon=False)
plt.yticks(size=12) # 设置y轴刻度,位置,大小plt.grid(axis="y", c=(217/256, 217/256, 217/256)) # 设置网格线# 将y轴网格线置于底层# plt.xlabel("Quarter",labelpad=10,size=18,) #设置x轴标签,labelpad设置标签距离x轴的位置# plt.ylabel("Amount",labelpad=10,size=18,) #设置y轴标签,labelpad设置标签距离y轴的位置
ax = plt.gca() ax.spines['top'].set_color('none') # 设置上‘脊梁’为无色ax.spines['right'].set_color('none') # 设置右‘脊梁’为无色ax.spines['left'].set_color('none') # 设置左‘脊梁’为无色
plt.show()效果如下所示:
1.3、堆积柱形图
通过一个示例了解堆积柱形图的使用,实现代码如下所示:
Sum_df = df.apply(lambda x: x.sum(), axis=0).sort_values(ascending=False)df = df.loc[:, Sum_df.index]
meanRow_df = df.apply(lambda x: x.mean(), axis=1)Sing_df = meanRow_df.sort_values(ascending=False).index
n_row, n_col = df.shape# x_label=np.array(df.columns)x_value = np.arange(n_col)
cmap = cm.get_cmap('YlOrRd_r', n_row)color = [colors.rgb2hex(cmap(i)[:3]) for i in range(cmap.N)]
bottom_y = np.zeros(n_col)
fig = plt.figure(figsize=(5, 5))#plt.subplots_adjust(left=0.1, right=0.9, top=0.7, bottom=0.1)
for i in range(n_row): label = Sing_df[i] plt.bar(x_value, df.loc[label, :], bottom=bottom_y, width=0.5, color=color[i], label=label, edgecolor='k', linewidth=0.25) bottom_y = bottom_y+df.loc[label, :].values
plt.xticks(x_value, df.columns, size=10) # 设置x轴刻度# plt.tick_params(axis="x",width=5)
plt.legend(loc=(1, 0.3), ncol=1, frameon=False)
plt.grid(axis="y", c=(166/256, 166/256, 166/256))
ax = plt.gca() # 获取整个表格边框ax.spines['top'].set_color('none') # 设置上‘脊梁’为无色ax.spines['right'].set_color('none') # 设置右‘脊梁’为无色ax.spines['left'].set_color('none') # 设置左‘脊梁’为无色
plt.show()效果如下所示:
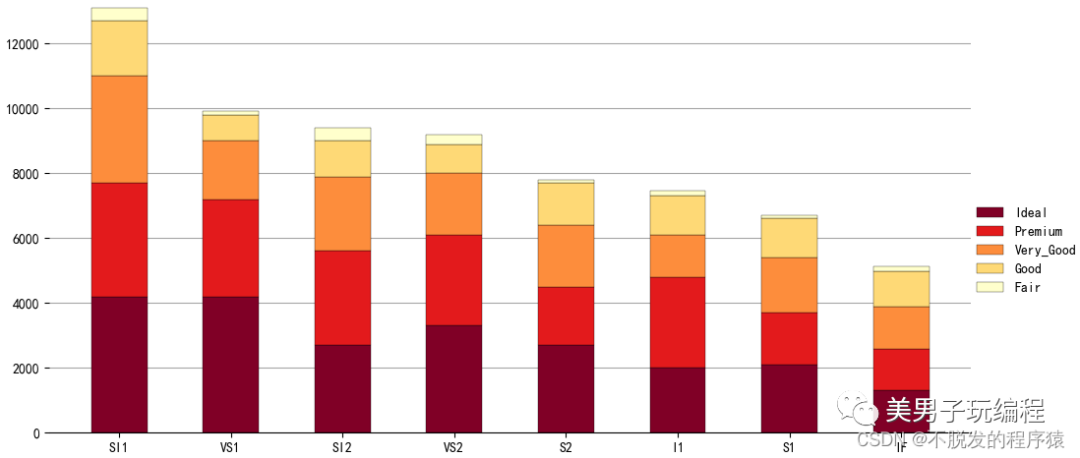
1.4、百分比堆积柱形图
通过一个示例了解百分比堆积柱形图的使用,实现代码如下所示:
SumCol_df = df.apply(lambda x: x.sum(), axis=0)
df = df.apply(lambda x: x/SumCol_df, axis=1)
meanRow_df = df.apply(lambda x: x.mean(), axis=1)
Per_df = df.loc[meanRow_df.idxmax(), :].sort_values(ascending=False)
Sing_df = meanRow_df.sort_values(ascending=False).index
df = df.loc[:, Per_df.index]
n_row, n_col = df.shape
x_value = np.arange(n_col)
cmap = cm.get_cmap('YlOrRd_r', n_row)color = [colors.rgb2hex(cmap(i)[:3]) for i in range(cmap.N)]
bottom_y = np.zeros(n_col)
fig = plt.figure(figsize=(5, 5))#plt.subplots_adjust(left=0.1, right=0.9, top=0.7, bottom=0.1)
for i in range(n_row): label = Sing_df[i] plt.bar(x_value, df.loc[label, :], bottom=bottom_y, width=0.5, color=color[i], label=label, edgecolor='k', linewidth=0.25) bottom_y = bottom_y+df.loc[label, :].values
plt.xticks(x_value, df.columns, size=10) # 设置x轴刻度plt.gca().set_yticklabels(['{:.0f}%'.format(x*100) for x in plt.gca().get_yticks()])
plt.legend(loc=(1, 0.3), ncol=1, frameon=False)
plt.grid(axis="y", c=(166/256, 166/256, 166/256))
ax = plt.gca() # 获取整个表格边框ax.spines['top'].set_color('none') # 设置上‘脊梁’为无色ax.spines['right'].set_color('none') # 设置右‘脊梁’为无色ax.spines['left'].set_color('none') # 设置左‘脊梁’为无色
plt.show()效果如下所示:
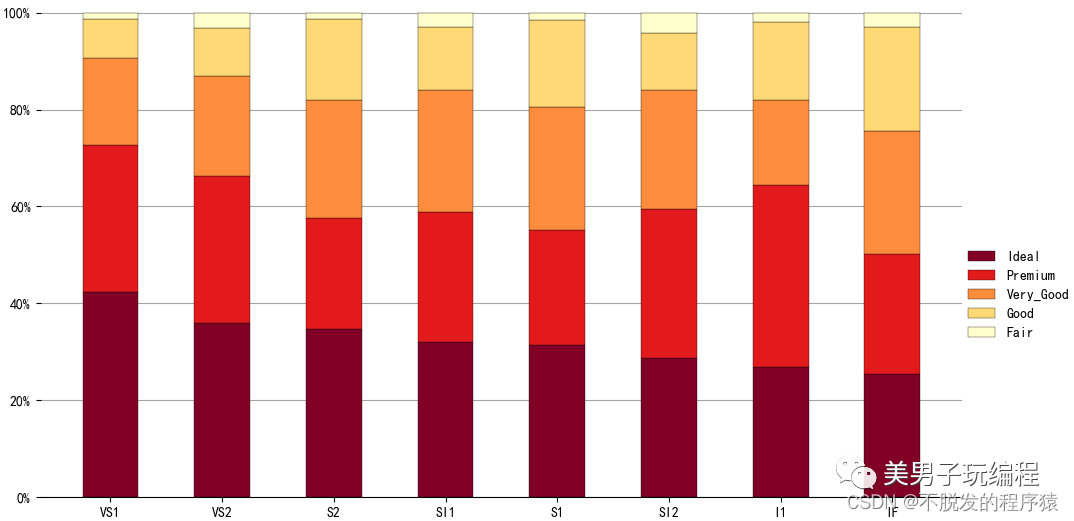
1.5、不等宽柱形图
有时候,我们需要在柱形图中同时表达两个维度的数据,除了每个柱形的高度表达了某个对象的数值大小(Y轴纵坐标),还希望柱形的宽度也能表达该对象的另外一个数值大小(X轴横坐标),以便直观地比较这两个维度。这时可以使用不等宽柱形图(variablewidth column chart)来展示数据,如下图所示:
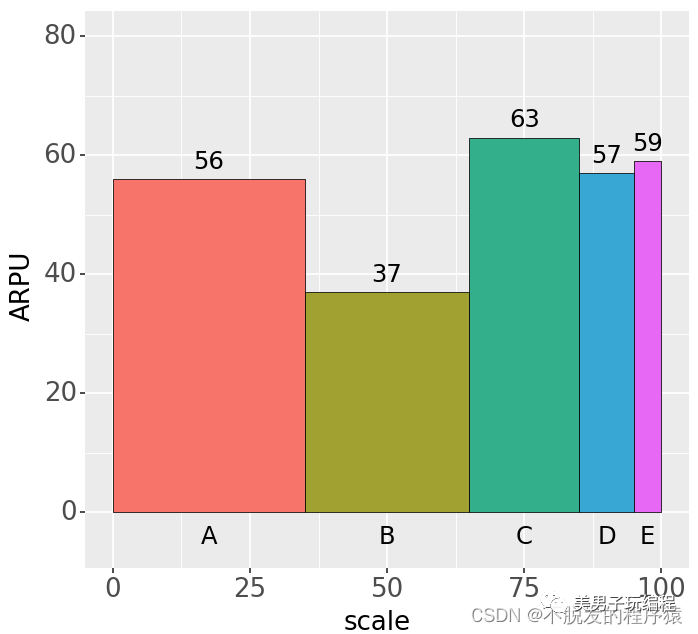
不等宽柱形图是常规柱形图的一种变化形式,它用柱形的高度反映一个数值的大小,同时用柱形的宽度反映另一个数值的大小,多用在市场调查研究、维度分析等方面。上图实现代码如下所示:
# -*- coding: utf-8 -*-# %%import pandas as pdimport numpy as npfrom plotnine import *
mydata = pd.DataFrame(dict(Name=['A', 'B', 'C', 'D', 'E'], Scale=[35, 30, 20, 10, 5], ARPU=[56, 37, 63, 57, 59]))
# 构造矩形X轴的起点(最小点)mydata['xmin'] = 0for i in range(1, 5): mydata['xmin'][i] = np.sum(mydata['Scale'][0:i])
# 构造矩形X轴的终点(最大点)mydata['xmax'] = 0for i in range(0, 5): mydata['xmax'][i] = np.sum(mydata['Scale'][0:i+1])
mydata['label'] = 0for i in range(0, 5): mydata['label'][i] = np.sum(mydata['Scale'][0:i+1])-mydata['Scale'][i]/2
base_plot = (ggplot(mydata) + geom_rect(aes(xmin='xmin', xmax='xmax', ymin=0, ymax='ARPU', fill='Name'), colour="black", size=0.25) + geom_text(aes(x='label', y='ARPU+3', label='ARPU'), size=14, color="black") + geom_text(aes(x='label', y=-4, label='Name'), size=14, color="black") + scale_fill_hue(s=0.90, l=0.65, h=0.0417, color_space='husl') + ylab("ARPU") + xlab("scale") + ylim(-5, 80) + theme( # panel_background=element_rect(fill="white"), #panel_grid_major = element_line(colour = "grey",size=.25,linetype ="dotted" ), #panel_grid_minor = element_line(colour = "grey",size=.25,linetype ="dotted" ), text=element_text(size=15), legend_position="none", aspect_ratio=1.15, figure_size=(5, 5), dpi=100))print(base_plot)2
条形图
条形图与柱形图类似,几乎可以表达相同多的数据信息。
在条形图中,类别型或序数型变量映射到纵轴的位置,数值型变量映射到矩形的宽度。条形图的柱形变为横向,从而导致与柱形图相比,条形图更加强调项目之间的大小对比。尤其在项目名称较长以及数量较多时,采用条形图可视化数据会更加美观、清晰,如下图所示:
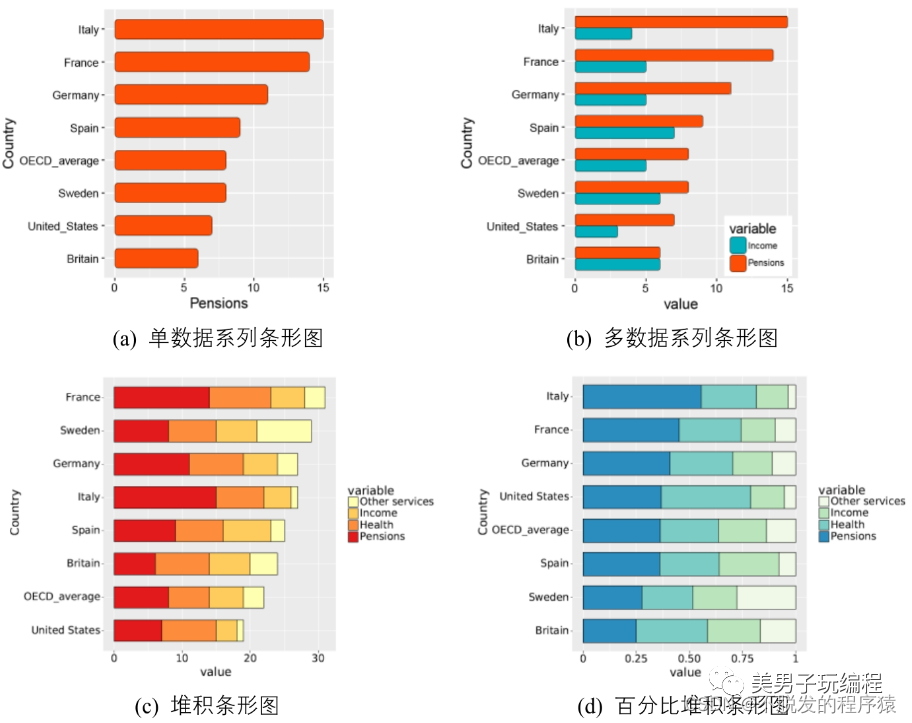
2.1、单数据系列条形图
通过一个示例了解单数据系列条形图的使用,实现代码如下所示:
df = pd.read_csv('Stackedbar_Data.csv')
df = df.sort_values(by='Pensions', ascending=True)
df['Country'] = pd.Categorical(df['Country'], categories=df['Country'], ordered=True)df
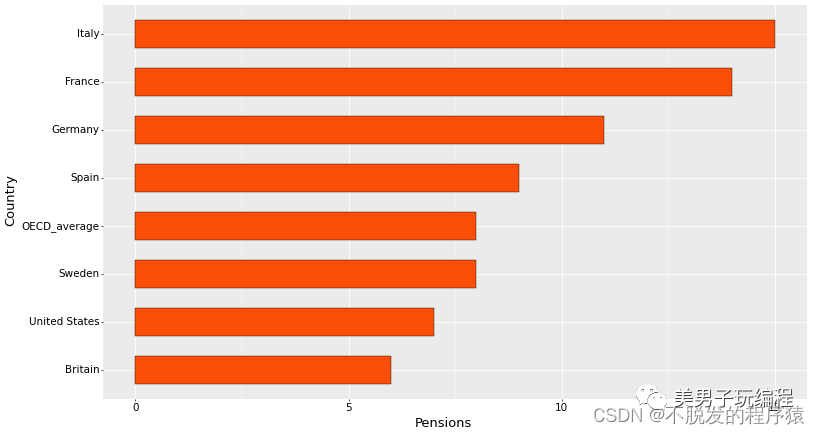
# %%base_plot = (ggplot(df, aes('Country', 'Pensions')) + # "#00AFBB" geom_bar(stat="identity", color="black", width=0.6, fill="#FC4E07", size=0.25) + # scale_fill_manual(values=brewer.pal(9,"YlOrRd")[c(6:2)])+ coord_flip() + theme( axis_title=element_text(size=15, face="plain", color="black"), axis_text=element_text(size=12, face="plain", color="black"), legend_title=element_text(size=13, face="plain", color="black"), legend_position="right", aspect_ratio=1.15, figure_size=(6.5, 6.5), dpi=50))
print(base_plot)实现效果如下所示:
2.2、多数据系列条形图
通过一个示例了解多数据系列条形图的使用,实现代码如下所示:
df = pd.read_csv('Stackedbar_Data.csv')
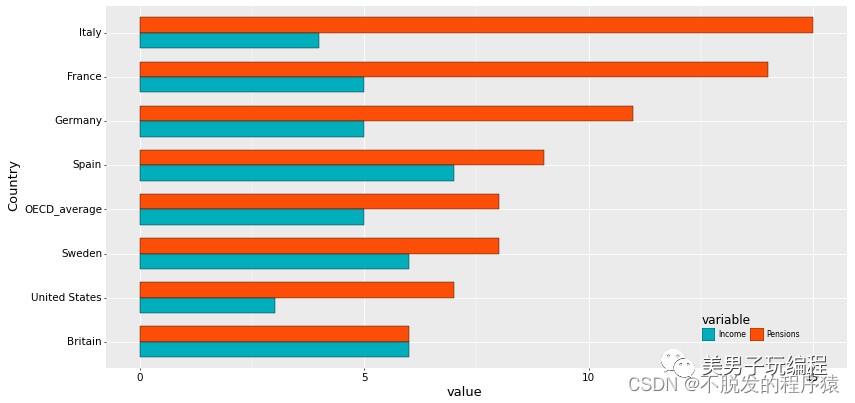
df = df.iloc[:, [0, 2, 1]]df = df.sort_values(by='Pensions', ascending=True)mydata = pd.melt(df, id_vars='Country')
mydata['Country'] = pd.Categorical(mydata['Country'], categories=df['Country'], ordered=True)
base_plot = (ggplot(mydata, aes('Country', 'value', fill='variable')) + geom_bar(stat="identity", color="black", position=position_dodge(), width=0.7, size=0.25) + scale_fill_manual(values=("#00AFBB", "#FC4E07", "#E7B800")) + coord_flip() + theme( axis_title=element_text(size=15, face="plain", color="black"), axis_text=element_text(size=12, face="plain", color="black"), legend_title=element_text(size=14, face="plain", color="black"), legend_background=element_blank(), legend_position=(0.8, 0.2), aspect_ratio=1.15, figure_size=(6.5, 6.5), dpi=50))print(base_plot)效果如下所示:
2.3、堆积条形图
通过一个示例了解堆积条形图的使用,实现代码如下所示:
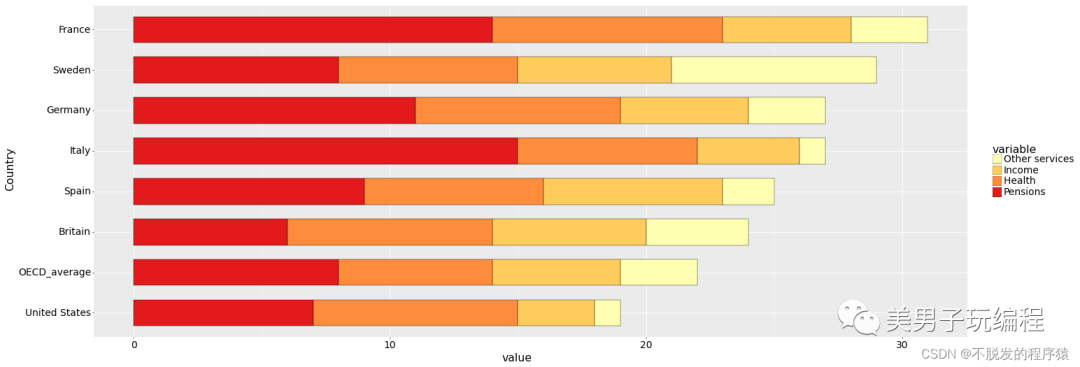
df = pd.read_csv('Stackedbar_Data.csv')Sum_df = df.iloc[:, 1:].apply( lambda x: x.sum(), axis=0).sort_values(ascending=True)meanRow_df = df.iloc[:, 1:].apply(lambda x: x.mean(), axis=1)Sing_df = df['Country'][meanRow_df.sort_values(ascending=True).index]mydata = pd.melt(df, id_vars='Country')mydata['variable'] = pd.Categorical(mydata['variable'], categories=Sum_df.index, ordered=True)mydata['Country'] = pd.Categorical(mydata['Country'], categories=Sing_df, ordered=True)
base_plot = (ggplot(mydata, aes('Country', 'value', fill='variable')) + geom_bar(stat="identity", color="black", position='stack', width=0.65, size=0.25) + scale_fill_brewer(palette="YlOrRd") + coord_flip() + theme( axis_title=element_text(size=18, face="plain", color="black"), axis_text=element_text(size=16, face="plain", color="black"), legend_title=element_text(size=18, face="plain", color="black"), legend_text=element_text(size=16, face="plain", color="black"), legend_background=element_blank(), legend_position='right', aspect_ratio=1.15, figure_size=(6.5, 6.5), dpi=50))print(base_plot)效果如下所示:
2.4、百分比堆积条形图
通过一个示例了解百分比堆积条形图的使用,实现代码如下所示:
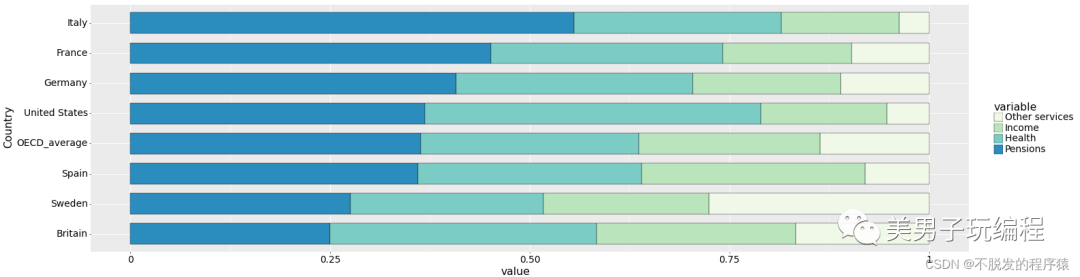
df = pd.read_csv('Stackedbar_Data.csv')SumCol_df = df.iloc[:, 1:].apply(lambda x: x.sum(), axis=1)df.iloc[:, 1:] = df.iloc[:, 1:].apply(lambda x: x/SumCol_df, axis=0)
meanRow_df = df.iloc[:, 1:].apply( lambda x: x.mean(), axis=0).sort_values(ascending=True)Per_df = df.loc[:, meanRow_df.idxmax()].sort_values(ascending=True)Sing_df = df['Country'][Per_df.index]
mydata = pd.melt(df, id_vars='Country')mydata['Country'] = pd.Categorical(mydata['Country'], categories=Sing_df, ordered=True)mydata['variable'] = pd.Categorical(mydata['variable'], categories=meanRow_df.index, ordered=True)
base_plot = (ggplot(mydata, aes(x='Country', y='value', fill='variable')) + geom_bar(stat="identity", color="black", position='fill', width=0.7, size=0.25) + scale_fill_brewer(palette="GnBu") + coord_flip() + theme( # text=element_text(size=15,face="plain",color="black"), axis_title=element_text(size=18, face="plain", color="black"), axis_text=element_text(size=16, face="plain", color="black"), legend_title=element_text(size=18, face="plain", color="black"), legend_text=element_text(size=16, face="plain", color="black"), aspect_ratio=1.15, figure_size=(6.5, 6.5), dpi=50))print(base_plot)效果如下所示:
3
雷达图
雷达图又称为蜘蛛图、极地图或星图,是用来比较多个定量变量的方法,可用于查看哪些变量具有相似数值,或者每个变量中有没有异常值。此外,雷达图也可用于查看数据集中哪些变量得分较高/低,是显示性能表现的理想之选。如下图所示:
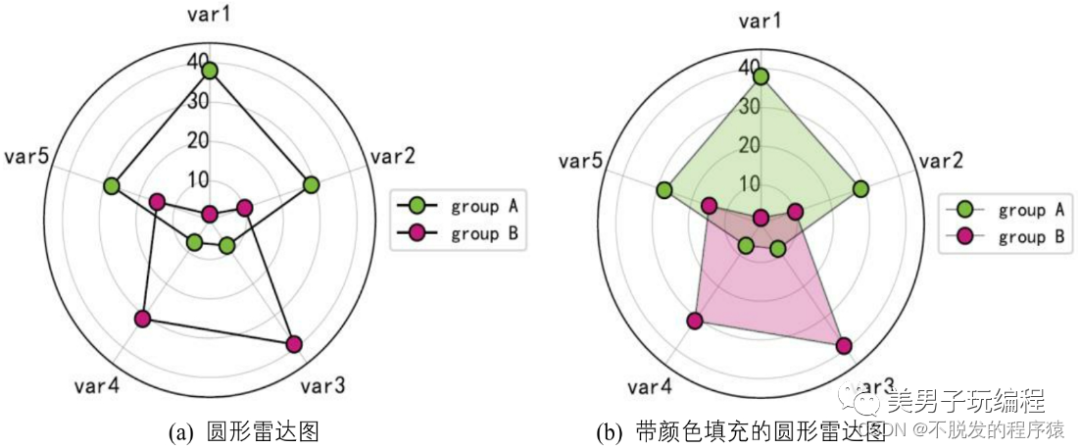
雷达图每个变量都具有自己的轴(从中心开始),所有的轴都以径向排列,彼此之间的距离相等,所有轴都有相同的刻度,轴与轴之间的网格线通常只是作为指引用途,每个变量数值会画在其所属轴线之上,数据集内的所有变量将连在一起形成一个多边形。
雷达图有一些重大缺点:
在一个雷达图中使用多个多边形,会令图表难以阅读,而且相当混乱。特别是如果用颜色填满多边形,那么表面的多边形会覆盖下面的其他多边形;
过多变量也会导致出现太多的轴线,使图表难以阅读和变得复杂,故雷达图只能保持简单,因而限制了可用变量的数量;
它未能很有效地比较每个变量的数值,即使借助蜘蛛网般的网格指引,也没有直线轴上比较数值容易。
通过一个示例了解雷达图的使用,实现代码如下所示:
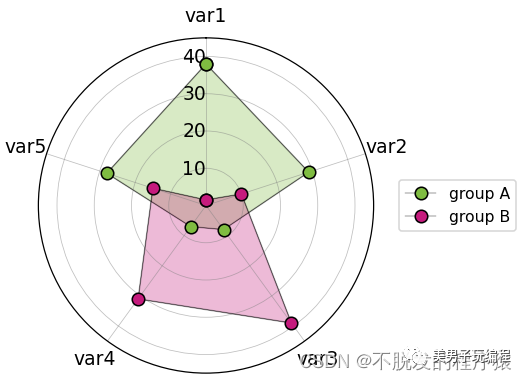
# -*- coding: utf-8 -*-# %%import numpy as npimport matplotlib.pyplot as pltimport pandas as pdfrom math import pifrom matplotlib.pyplot import figure, show, rcplt.rcParams["patch.force_edgecolor"] = True df = pd.DataFrame(dict(categories=['var1', 'var2', 'var3', 'var4', 'var5'], group_A=[ 38.0, 29, 8, 7, 28], group_B=[1.5, 10, 39, 31, 15]))N = df.shape[0]angles = [n / float(N) * 2 * pi for n in range(N)]angles += angles[:1] fig = figure(figsize=(4, 4), dpi=90)ax = fig.add_axes([0.1, 0.1, 0.6, 0.6], polar=True)ax.set_theta_offset(pi / 2)ax.set_theta_direction(-1)ax.set_rlabel_position(0)plt.xticks(angles[:-1], df['categories'], color="black", size=12)plt.ylim(0, 45)plt.yticks(np.arange(10, 50, 10), color="black", size=12, verticalalignment='center', horizontalalignment='right')plt.grid(which='major', axis="x", linestyle='-', linewidth='0.5', color='gray', alpha=0.5)plt.grid(which='major', axis="y", linestyle='-', linewidth='0.5', color='gray', alpha=0.5) values = df['group_A'].values.flatten().tolist()values += values[:1]ax.fill(angles, values, '#7FBC41', alpha=0.3)ax.plot(angles, values, marker='o', markerfacecolor='#7FBC41', markersize=8, color='k', linewidth=0.25, label="group A") values = df['group_B'].values.flatten().tolist()values += values[:1]ax.fill(angles, values, '#C51B7D', alpha=0.3)ax.plot(angles, values, marker='o', markerfacecolor='#C51B7D', markersize=8, color='k', linewidth=0.25, label="group B")plt.legend(loc="center", bbox_to_anchor=(1.25, 0, 0, 1)) plt.show()
效果如下所示:
4
词云图
词云图通过使每个字的大小与其出现频率成正比,显示不同单词在给定文本中的出现频率,这会过滤掉大量的文本信息,使浏览者只要一眼扫过文本就可以领略文本的主旨。
词云图会将所有的字词排在一起,形成云状图案,也可以任何格式排列:水平线、垂直列或其他形状,也可用于显示获分配元数据的单词。如下图所示:

词云图通常用于网站或博客上,用于描述关键字或标签,也可用来比较两个不同的文本。
词云图虽然简单易懂,但有着一些重大缺点:
较长的字词会更引人注意;
字母含有很多升部/降部的单词可能会更受人关注;
分析精度不足,较多时候是为了美观。
通过一个示例了解词云图的使用,实现代码如下所示:
# -*- coding: utf-8 -*-# %%import chardetimport jiebaimport numpy as npfrom PIL import Imageimport osfrom os import pathfrom wordcloud import WordCloud, STOPWORDS, ImageColorGeneratorfrom matplotlib import pyplot as pltfrom matplotlib.pyplot import figure, show, rc
# %%# -------------------------------------English-白色背景的方形词云图-----------------------------------------# 获取当前文件路径d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()# 获取文本texttext = open(path.join(d, 'WordCloud.txt')).read()# 生成词云#wc = WordCloud(scale=2,max_font_size = 100)wc = WordCloud(font_path=None, # 字体路径,英文不用设置路径,中文需要,否则无法正确显示图形 width=400, # 默认宽度 height=400, # 默认高度 margin=2, # 边缘 ranks_only=None, prefer_horizontal=0.9, mask=None, # 背景图形,如果想根据图片绘制,则需要设置 scale=2, color_func=None, max_words=100, # 最多显示的词汇量 min_font_size=4, # 最小字号 stopwords=None, # 停止词设置,修正词云图时需要设置 random_state=None, background_color='white', # 背景颜色设置,可以为具体颜色,比如white或者16进制数值 max_font_size=None, # 最大字号 font_step=1, mode='RGB', relative_scaling='auto', regexp=None, collocations=True, colormap='Reds', # matplotlib 色图,可更改名称进而更改整体风格 normalize_plurals=True, contour_width=0, contour_color='black', repeat=False)
wc.generate_from_text(text)# 显示图像
fig = figure(figsize=(4, 4), dpi=100)plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.tight_layout()# fig.savefig("词云图1.pdf")plt.show()
# %%# -------------------------------------中文-黑色背景的圆形词云图-----------------------------------------text = open(path.join(d, 'WordCloud_Chinese.txt'), 'rb').read()text_charInfo = chardet.detect(text)print(text_charInfo)# 结果#{'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}text = open(path.join(d, r'WordCloud_Chinese.txt'), encoding='GB2312', errors='ignore').read()
# 获取文本词排序,可调整 stopwordsprocess_word = WordCloud.process_text(wc, text)sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)print(sort[:50]) # 获取文本词频最高的前50个词
text += ' '.join(jieba.cut(text, cut_all=False)) # cut_all=False 表示采用精确模式# 设置中文字体font_path = 'SourceHanSansCN-Regular.otf' # 思源黑体# 读取背景图片background_Image = np.array(Image.open(path.join(d, "WordCloud_Image.jpg")))# 提取背景图片颜色img_colors = ImageColorGenerator(background_Image)# 设置中文停止词stopwords = set('')stopwords.update(['但是', '一个', '自己', '因此', '没有', '很多', '可以', '这个', '虽然', '因为', '这样', '已经', '现在', '一些', '比如', '不是', '当然', '可能', '如果', '就是', '同时', '比如', '这些', '必须', '由于', '而且', '并且', '他们'])
wc = WordCloud( font_path=font_path, # 中文需设置路径 # width=400, # 默认宽度 # height=400, # 默认高度 margin=2, # 页面边缘 mask=background_Image, scale=2, max_words=200, # 最多词个数 min_font_size=4, stopwords=stopwords, random_state=42, background_color='black', # 背景颜色 # background_color = '#C3481A', # 背景颜色 colormap='RdYlGn_r', # matplotlib 色图,可更改名称进而更改整体风格 max_font_size=100,)wc.generate(text)# 获取文本词排序,可调整 stopwordsprocess_word = WordCloud.process_text(wc, text)sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)print(sort[:50]) # 获取文本词频最高的前50个词# 设置为背景色,若不想要背景图片颜色,就注释掉# wc.recolor(color_func=img_colors)# 存储图像# wc.to_file('浪潮之巅basic.png')# 显示图像fig = figure(figsize=(4, 4), dpi=100)plt.imshow(wc, interpolation='bilinear')plt.axis('off')plt.tight_layout()
# fig.savefig("词云图2.pdf")
plt.show()效果如下所示:


5
克利夫兰点图
在讲解克利夫兰点图时需要延升讲解一下棒棒图和哑铃图,如下图所示:
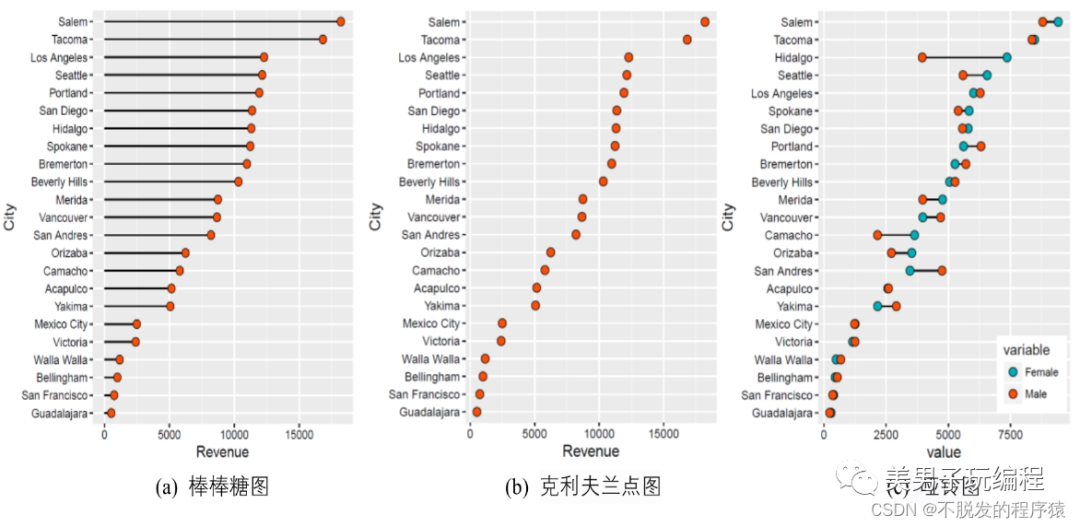
从图形效果来看,棒棒图、克利夫兰点图和哑铃图十分相像,因为本质上来看棒棒图和哑铃图也属于克利夫兰点图。
棒棒糖图传达了与柱形图或条形图相同的信息,只是将矩形转变成线条,这样可以减少展示空间,重点放在数据点上,从而看起来更加简洁与美观。相对于柱形图与条形图,棒棒糖图更加适合数据量比较多的情况;
克利夫兰点图也是滑珠散点图,非常类似于棒棒糖图,只是没有连接的线条,重点强调数据的排序展示以及互相之间的差距;
哑铃图可以看作多数据系列的克利夫兰点图,只是使用直线连接了两个数据系列的数据点。哑铃图主要用于:1、展示在同一时间段两个数据点的相对位置(增加或者减少);2、比较两个类别之间的数据值差别。
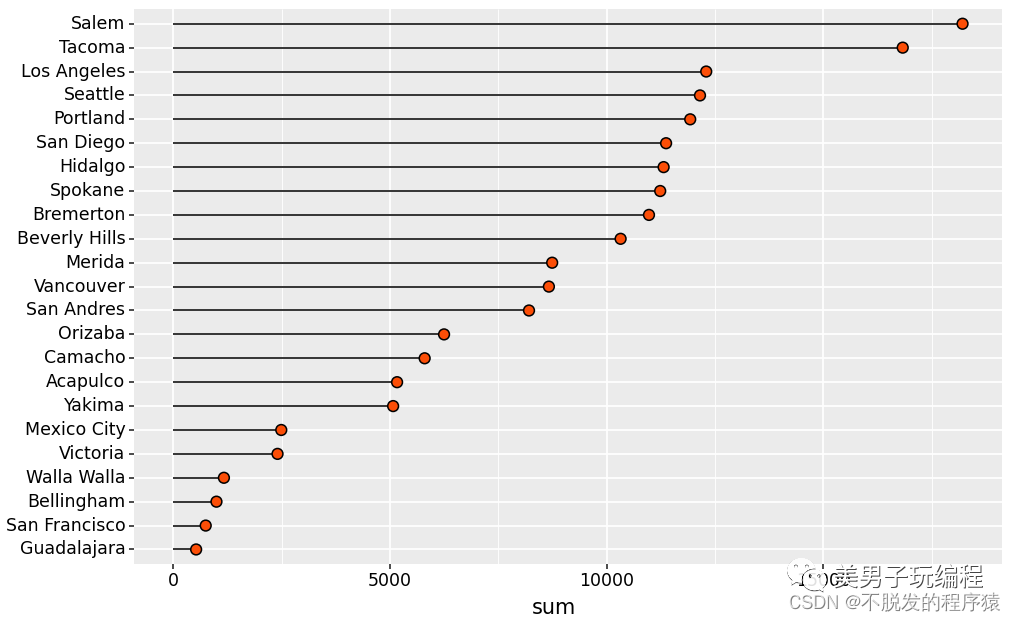
5.1、棒棒糖图
通过一个示例了解棒棒糖图的使用,实现代码如下所示:
df = pd.read_csv('DotPlots_Data.csv')
df['sum'] = df.iloc[:, 1:3].apply(np.sum, axis=1)
df = df.sort_values(by='sum', ascending=True)df['City'] = pd.Categorical(df['City'], categories=df['City'], ordered=True)df
# %%base_plot = (ggplot(df, aes('sum', 'City')) + geom_segment(aes(x=0, xend='sum', y='City', yend='City')) + geom_point(shape='o', size=3, colour="black", fill="#FC4E07") + theme( axis_title=element_text(size=12, face="plain", color="black"), axis_text=element_text(size=10, face="plain", color="black"), # legend_title=element_text(size=14,face="plain",color="black"), aspect_ratio=1.25, figure_size=(4, 4), dpi=100))
print(base_plot)效果如下所示:
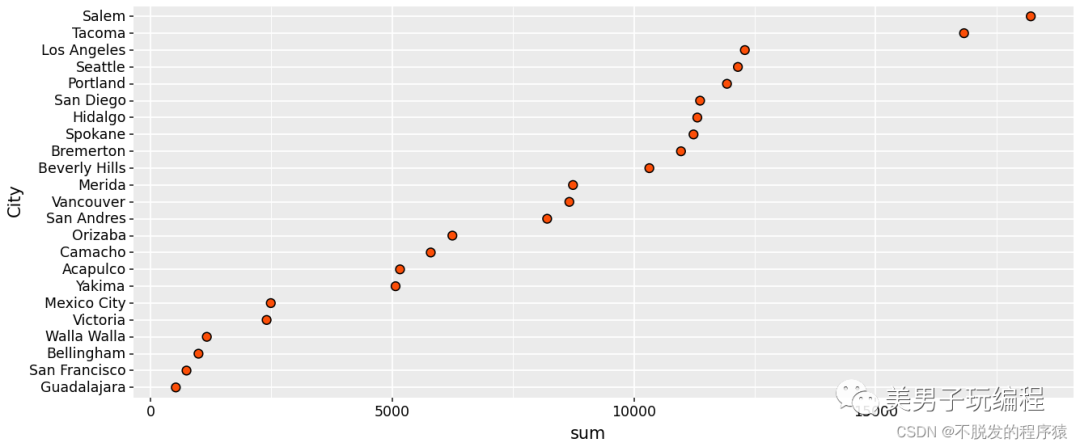
5.2、克利夫兰点图
通过一个示例了解克利夫兰点图的使用,实现代码如下所示:
base_plot = (ggplot(df, aes('sum', 'City')) +
geom_point(shape='o', size=3, colour="black", fill="#FC4E07") + theme( axis_title=element_text(size=12, face="plain", color="black"), axis_text=element_text(size=10, face="plain", color="black"), # legend_title=element_text(size=14,face="plain",color="black"), aspect_ratio=1.25, figure_size=(4, 4), dpi=100))
print(base_plot)效果如下所示:
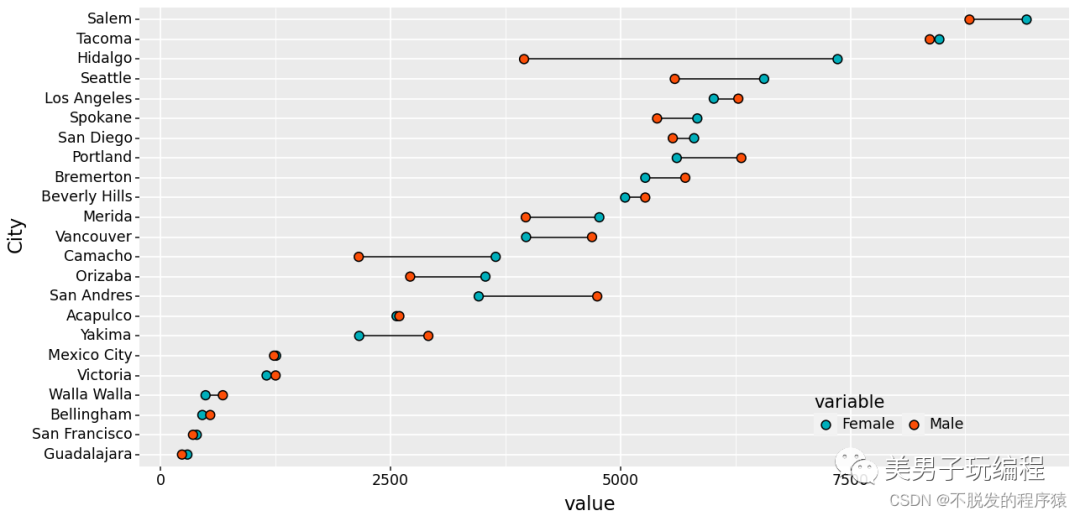
5.3、哑铃图
通过一个示例了解哑铃图的使用,实现代码如下所示:
df = pd.read_csv('DotPlots_Data.csv')
df = df.sort_values(by='Female', ascending=True)df['City'] = pd.Categorical(df['City'], categories=df['City'], ordered=True)mydata = pd.melt(df, id_vars='City')
base_plot = (ggplot(mydata, aes('value', 'City', fill='variable')) + geom_line(aes(group='City')) + geom_point(shape='o', size=3, colour="black") + scale_fill_manual(values=("#00AFBB", "#FC4E07", "#36BED9")) + theme( axis_title=element_text(size=13, face="plain", color="black"), axis_text=element_text(size=10, face="plain", color="black"), legend_title=element_text(size=12, face="plain", color="black"), legend_text=element_text(size=10, face="plain", color="black"), legend_background=element_blank(), legend_position=(0.75, 0.2), aspect_ratio=1.25, figure_size=(4, 4), dpi=100))
print(base_plot)效果如下所示:
6
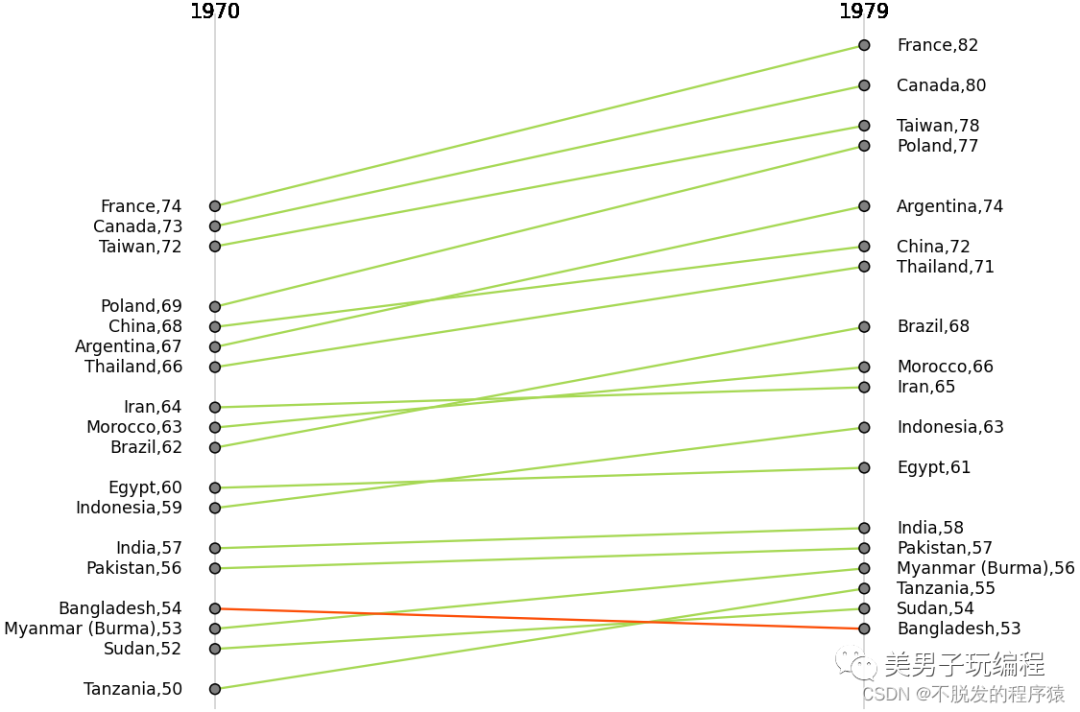
坡度图
坡度图顾名思义是展示坡度变化的图形,其实他和哑铃图有异曲同工之处,只不过坡度图可以更加清楚的展示数据前后的变化趋势,具体是增加了还是减少了。
通过一个示例了解坡度图的使用,实现代码如下所示:
base_plot = (ggplot(df) + # 连接线 geom_segment(aes(x=1, xend=2, y='1970', yend='1979', color='class'), size=.75, show_legend=False) + # 1952年的垂直直线 geom_vline(xintercept=1, linetype="solid", size=.1) + # 1957年的垂直直线 geom_vline(xintercept=2, linetype="solid", size=.1) + # 1952年的数据点 geom_point(aes(x=1, y='1970'), size=3, shape='o', fill="grey", color="black") + # 1957年的数据点 geom_point(aes(x=2, y='1979'), size=3, shape='o', fill="grey", color="black") + scale_color_manual(labels=("Up", "Down"), values=("#A6D854", "#FC4E07")) + xlim(.5, 2.5))# 添加文本信息base_plot = (base_plot + geom_text(label=left_label, y=df['1970'], x=0.95, size=10, ha='right') + geom_text(label=right_label, y=df['1979'], x=2.05, size=10, ha='left') + geom_text(label="1970", x=1, y=1.02 * (np.max(np.max(df[['1970', '1979']]))), size=12) + geom_text(label="1979", x=2, y=1.02 * (np.max(np.max(df[['1970', '1979']]))), size=12) + theme_void() + theme( aspect_ratio=1.5, figure_size=(5, 6), dpi=100))print(base_plot)效果如下所示:
7
径向柱图
径向柱图也称为圆形柱图或星图,这种图表使用同心圆网格来绘制条形图,如下图所示:
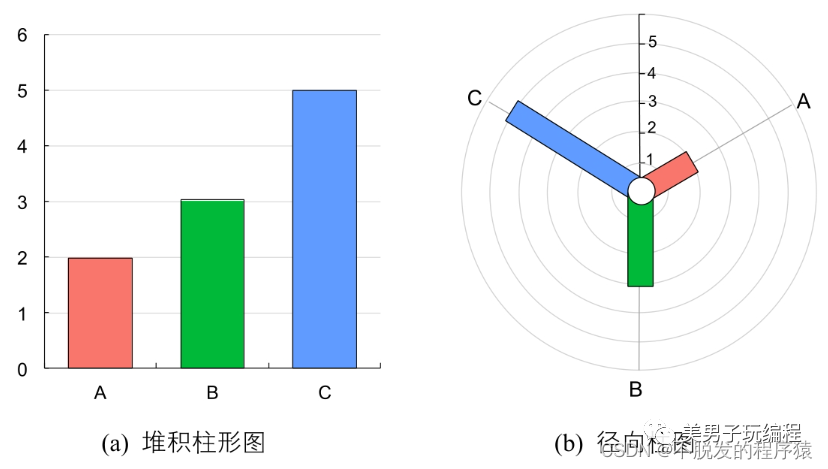
每个圆圈表示一个数值刻度,而径向分隔线(从中心延伸出来的线)则用于区分不同类别或间隔(如果是直方图)。刻度上较低的数值通常由中心点开始,然后数值会随着每个圆形往外增加,但也可以把任何外圆设为零值,这样里面的内圆就可用来显示负值。条形通常从中心点开始向外延伸,但也可以以别处为起点,显示数值范围(如跨度图)。
此外,条形也可以如堆叠式条形图般堆叠起来,如下图所示:
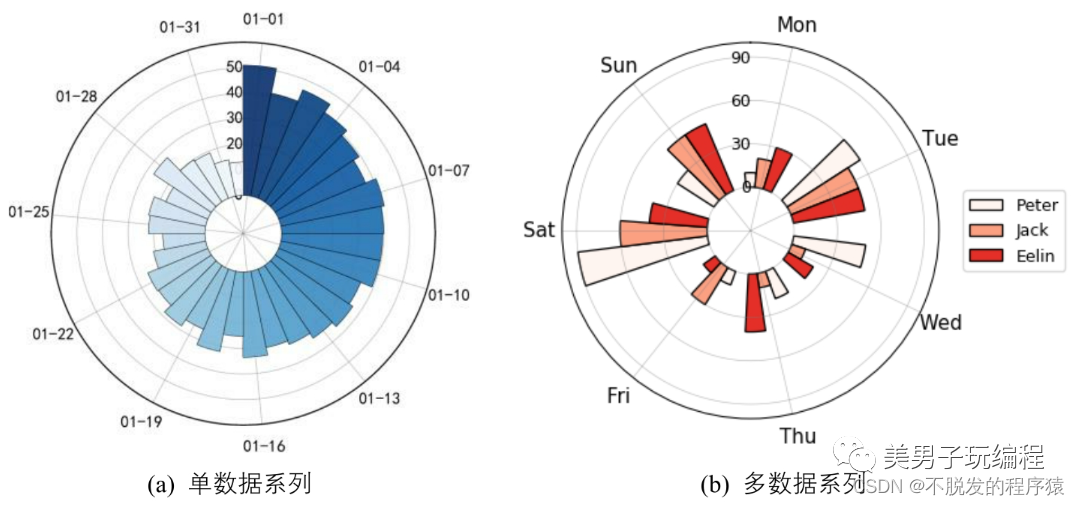
通过一个示例了解单数据径向柱图的使用,实现代码如下所示:
import datetimeimport numpy as npfrom matplotlib import cm, colorsfrom matplotlib import pyplot as pltfrom matplotlib.pyplot import figure, show, rcimport pandas as pdplt.rcParams["patch.force_edgecolor"] = True# plt.rc('axes',axisbelow=True)plt.rcParams['axes.axisbelow'] = True
def dateRange(beginDate, endDate): dates = [] dt = datetime.datetime.strptime(beginDate, "%Y-%m-%d") date = beginDate[:] while date <= endDate: dates.append(date) dt = dt + datetime.timedelta(1) date = dt.strftime("%Y-%m-%d") return dates
mydata = pd.DataFrame(dict(day=dateRange("2016-01-01", "2016-02-01"), Price=-np.sort(-np.random.normal(loc=30, scale=10, size=32)) + np.random.normal(loc=3, scale=3, size=32)))
mydata['day'] = pd.to_datetime(mydata['day'], format="%Y/%m/%d")mydata
# %%n_row = mydata.shape[0]angle = np.arange(0, 2*np.pi, 2*np.pi/n_row)radius = np.array(mydata.Price)
fig = figure(figsize=(4, 4), dpi=90)ax = fig.add_axes([0.1, 0.1, 0.8, 0.8], polar=True)
# 方法用于设置角度偏离,参数值为弧度值数值ax.set_theta_offset(np.pi/2-np.pi/n_row)# 当set_theta_direction的参数值为1,'counterclockwise'或者是'anticlockwise'的时候,正方向为逆时针;# 当set_theta_direction的参数值为-1或者是'clockwise'的时候,正方向为顺时针;ax.set_theta_direction(-1)# 方法用于设置极径标签显示位置,参数为标签所要显示在的角度ax.set_rlabel_position(360-180/n_row)
cmap = cm.get_cmap('Blues_r', n_row)color = [colors.rgb2hex(cmap(i)[:3]) for i in range(cmap.N)]
plt.bar(angle, radius, color=color, alpha=0.9, width=0.2, align="center", linewidth=0.25)
plt.ylim(-15, 60)index = np.arange(0, n_row, 3)plt.xticks(angle[index], labels=[x.strftime('%m-%d') for x in mydata.day[index]], size=12)plt.yticks(np.arange(0, 60, 10), verticalalignment='center', horizontalalignment='right')
plt.grid(which='major', axis="x", linestyle='-', linewidth='0.5', color='gray', alpha=0.5)plt.grid(which='major', axis="y", linestyle='-', linewidth='0.5', color='gray', alpha=0.5)
plt.show()效果如下所示:
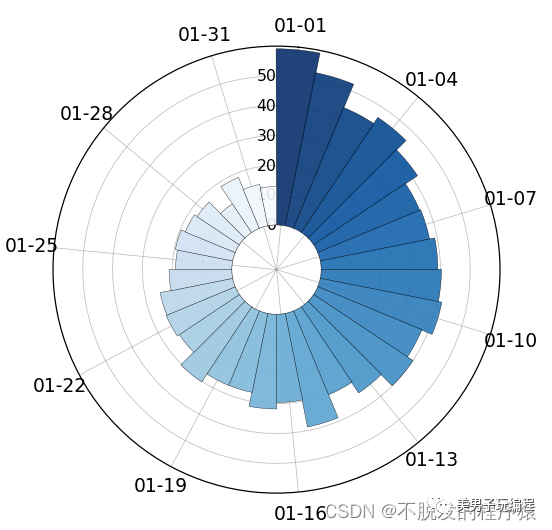
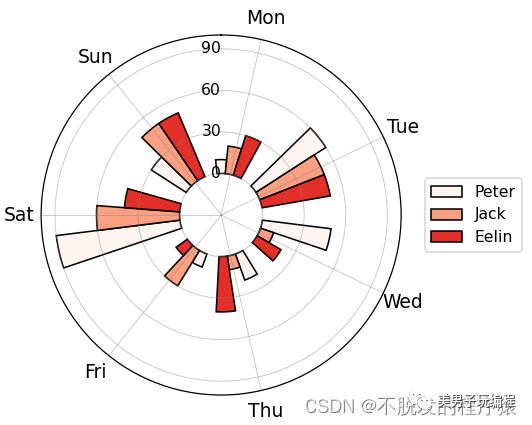
通过一个示例了解多数据径向柱图的使用,实现代码如下所示:
import numpy as npfrom matplotlib import cm, colorsfrom matplotlib import pyplot as pltfrom matplotlib.pyplot import figure, show, rcimport pandas as pd
plt.rcParams["patch.force_edgecolor"] = True
mydata = pd.DataFrame(dict(day=["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"], Peter=[10, 60, 50, 20, 10, 90, 30], Jack=[20, 50, 10, 10, 30, 60, 50], Eelin=[30, 50, 20, 40, 10, 40, 50]))
n_row = mydata.shape[0]n_col = mydata.shape[1]angle = np.arange(0, 2*np.pi, 2*np.pi/n_row)# 绘制的数据
cmap = cm.get_cmap('Reds', n_col)color = [colors.rgb2hex(cmap(i)[:3]) for i in range(cmap.N)]
radius1 = np.array(mydata.Peter)radius2 = np.array(mydata.Jack)radius3 = np.array(mydata.Eelin)
fig = figure(figsize=(4, 4), dpi=90)ax = fig.add_axes([0.1, 0.1, 0.8, 0.8], polar=True)
# 方法用于设置角度偏离,参数值为弧度值数值ax.set_theta_offset(np.pi/2)# 当set_theta_direction的参数值为1,'counterclockwise'或者是'anticlockwise'的时候,正方向为逆时针;# 当set_theta_direction的参数值为-1或者是'clockwise'的时候,正方向为顺时针;ax.set_theta_direction(-1)# 方法用于设置极径标签显示位置,参数为标签所要显示在的角度ax.set_rlabel_position(360)
barwidth1 = 0.2barwidth2 = 0.2plt.bar(angle, radius1, width=barwidth2, align="center", color=color[0], edgecolor="k", alpha=1, label="Peter")plt.bar(angle+barwidth1, radius2, width=barwidth2, align="center", color=color[1], edgecolor="k", alpha=1, label="Jack")plt.bar(angle+barwidth1*2, radius3, width=barwidth2, align="center", color=color[2], edgecolor="k", alpha=1, label="Eelin")
plt.legend(loc="center", bbox_to_anchor=(1.2, 0, 0, 1))
plt.ylim(-30, 100)plt.xticks(angle+2*np.pi/n_row/4, labels=mydata.day, size=12)
plt.yticks(np.arange(0, 101, 30), verticalalignment='center', horizontalalignment='right')
plt.grid(which='major', axis="x", linestyle='-', linewidth='0.5', color='gray', alpha=0.5)plt.grid(which='major', axis="y", linestyle='-', linewidth='0.5', color='gray', alpha=0.5)
plt.show()实现效果如下所示:
8
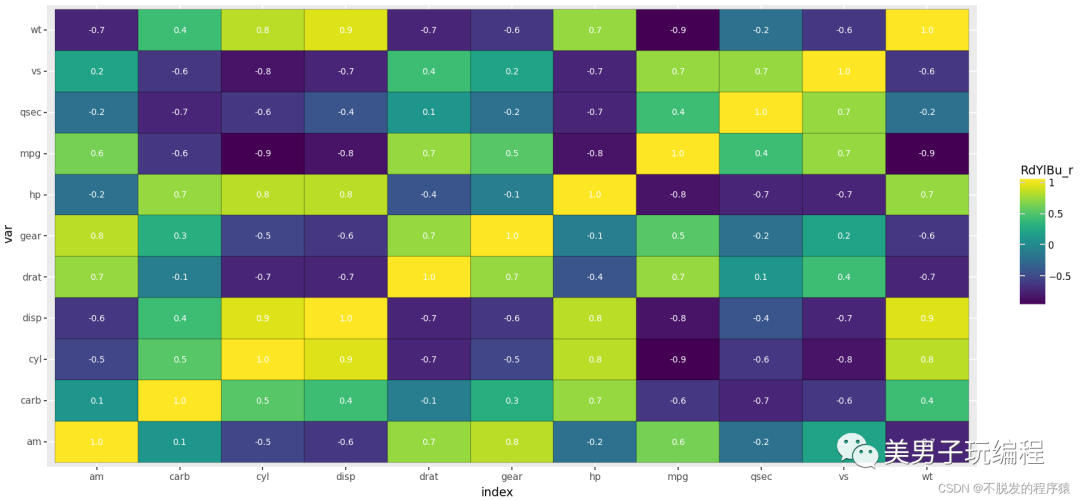
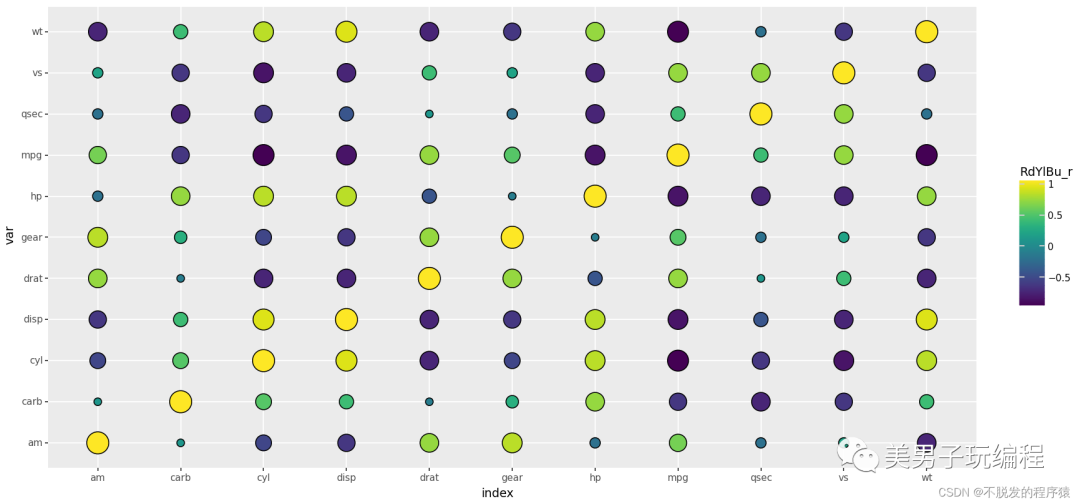
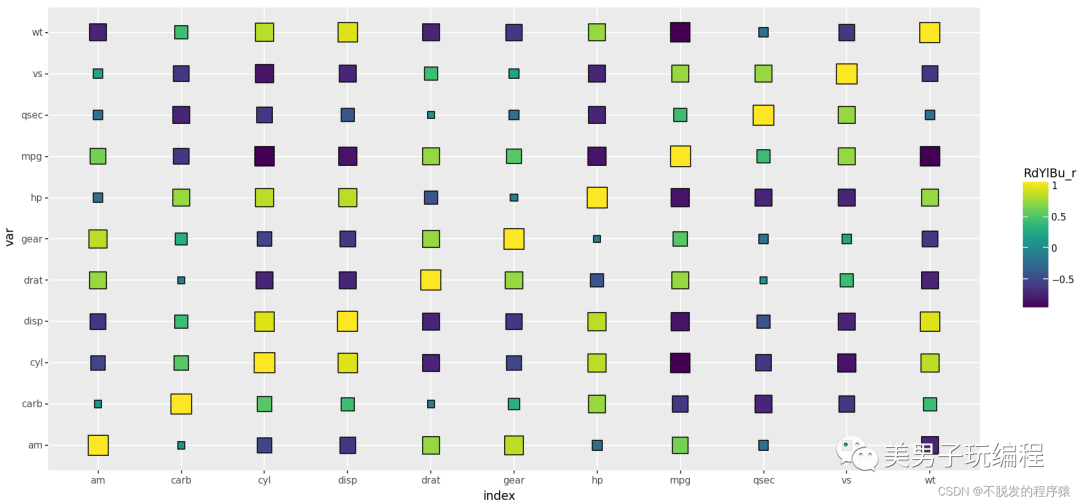
热力图
热力图是一种通过对色块着色来显示数据的统计图表,绘图时需指定颜色映射的规则。例如,较大的值由较深的颜色表示,较小的值由较浅的颜色表示;较大的值由偏暖的颜色表示,较小的值由较冷的颜色表示等。
通过一个示例了解热力图的使用,实现代码如下所示:
import numpy as npimport pandas as pdfrom plotnine import *from plotnine.data import mtcars mat_corr = np.round(mtcars.corr(), 1).reset_index()mydata = pd.melt(mat_corr, id_vars='index', var_name='var', value_name='value')mydata # %%base_plot = (ggplot(mydata, aes(x='index', y='var', fill='value', label='value')) + geom_tile(colour="black") + geom_text(size=8, colour="white") + scale_fill_cmap(name='RdYlBu_r') + coord_equal() + theme(dpi=100, figure_size=(4, 4)))print(base_plot) # %%mydata['AbsValue'] = np.abs(mydata.value) base_plot = (ggplot(mydata, aes(x='index', y='var', fill='value', size='AbsValue')) + geom_point(shape='o', colour="black") + # geom_text(size=8,colour="white")+ scale_size_area(max_size=11, guide=False) + scale_fill_cmap(name='RdYlBu_r') + coord_equal() + theme(dpi=100, figure_size=(4, 4)))print(base_plot) # %%base_plot = (ggplot(mydata, aes(x='index', y='var', fill='value', size='AbsValue')) + geom_point(shape='s', colour="black") + # geom_text(size=8,colour="white")+ scale_size_area(max_size=10, guide=False) + scale_fill_cmap(name='RdYlBu_r') + coord_equal() + theme(dpi=100, figure_size=(4, 4)))print(base_plot)
效果如下所示:
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。