
要打破内存墙,可以将HBM与DDR5融合
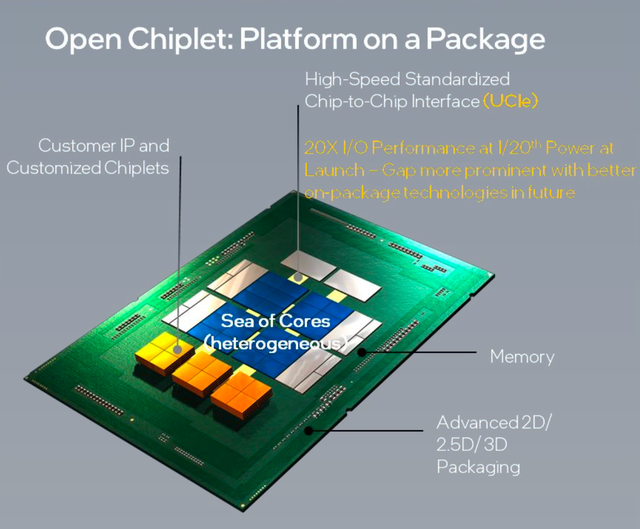
在 2024 年,如果需要将数十个、数百个、数千个甚至数万个加速器拼接在一起,那么互连就是个大课题了。
本文引用地址:http://www.amcfsurvey.com/article/202404/457233.htm英伟达(Nvidia) 拥有 NVLink 和 InfiniBand。Google 的 TPU 吊舱使用光电路开关(OCS)相互通信。AMD 拥有 Infinity Fabric,用于芯片到芯片、芯片到芯片以及即将推出的节点到节点流量。当然,还有好的老式以太网。
这里的诀窍不是构建足够大的网格,而是抵御与离包相关的大量性能损失和带宽瓶颈。它也没有做任何事情来解决这样一个事实,即所有这些 AI 处理所依赖的 HBM 内存都以固定的比例与计算相关联。
「这个行业正在使用 Nvidia GPU 作为世界上最昂贵的内存控制器,」Dave Lazovsky 说,他的公司 Celestial AI 刚刚在 USIT 和许多其他风险投资巨头支持的 C 轮融资中获得了 1.75 亿美元,以将其光子织物商业化。
去年夏天,我们研究了 Celestial 的光子结构,其中包括一系列硅光子学互连器、中介层和小芯片,旨在将 AI 计算从内存中分解出来。不到一年后,他们正在与几家超大规模客户和一家大型处理器制造商合作,将其技术集成到他们的产品中。Lazovsky 没有指名道姓。
但事实上,Celestial 将 AMD Ventures 视为其支持者之一,其高级副总裁兼产品技术架构师 Sam Naffziger 在公告发布的同一天讨论了共同封装硅光子小芯片的可能性,这无疑引起了一些人的注意。话虽如此,AMD 为光子学初创公司提供资金并不意味着我们将永远在 Epyc CPU 或 Instinct GPU 加速器中看到 Celestial 的小芯片。
虽然 Lazovsky 无法透露 Celestial 与谁合作,但他确实提供了一些关于该技术如何集成的线索,以及即将推出的 HBM 内存设备的先睹为快。
正如我们在最初涉足 Celestial 的产品战略时所讨论的那样,该公司的零件分为三大类:小芯片、中介层和英特尔 EMIB 或台积电 CoWoS 的光学旋转,称为 OMIB。
不出所料,Celestial 的大部分吸引力都集中在小芯片上。「我们没有做的是试图强迫我们的客户采用任何一种特定的产品实施。目前,为光子结构提供接口的风险最低、最快、最不复杂的方法是通过小芯片,「Lazovsky 告诉 The Next Platform。
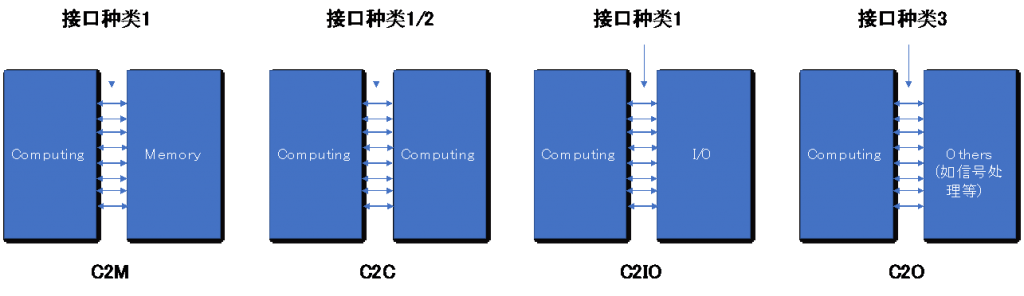
从广义上讲,这些小芯片可以以两种方式使用:要么增加额外的 HBM 内存容量,要么作为芯片到芯片的互连,分类或类似于光学 NVLink 或 Infinity Fabric。
这些小芯片比 HBM 堆栈小一点,提供光电互连,片外总带宽为 14.4 Tb/s 或 1.8 GB/s。
话虽如此,我们被告知可以制造一个小芯片来支持更高的带宽。第一代技术可以支持每平方毫米约 1.8 Tb/s 的速度。与此同时,Celestial 的第二代 Photonic 结构将从 56 Gb/s 提高到 112 Gb/s 的 PAM4 SerDes,并将通道数量从 4 个增加到 8 个,从而有效地将带宽翻两番。
因此,14.4 Tb/s 不是上限,而是现有芯片架构能够处理的结果。这是有道理的,否则任何额外的容量都会被浪费。
这种连接性意味着 Celestial 可以实现类似于 NVLink 的互连速度,只是沿途的步骤更少。
虽然芯片到芯片的连接相对不言自明——在每个封装上放一个光子织物小芯片并对齐光纤连接——但内存扩展完全是另一种动物。虽然 14.4 Tb/s 的速度并不慢,但对于多个 HBM3 或 HBM3e 堆栈来说,它仍然是一个瓶颈。这意味着添加更多的 HBM 只会让您的容量超过某个点。尽管如此,用两个 HBM3e 堆栈代替一个堆栈并不算什么。
Celestial 有一个有趣的解决方法,即它的内存扩展模块。由于带宽的上限为 1.8 GB/s,因此该模块将仅包含两个总计 72 GB 的 HBM 堆栈。此外,还将配备一组 4 个 DDR5 DIMM,支持高达 2 TB 的额外容量。
Lazovsky 不愿将所有豆子都洒在产品上,但确实告诉我们,它将使用 Celestial 的硅光子学中介层技术作为 HBM,互连和控制器逻辑之间的接口。
说到模块的控制器,我们被告知 5nm 开关 ASIC 有效地将 HBM 变成 DDR5 的直写缓存。「它为您提供了 DDR 的容量和成本以及带宽和 HBM 互连的 32 个伪通道的所有优势,从而隐藏了延迟,」Lazovsky 解释道。
他补充说,这与英特尔对至强 Max 所做的或英伟达对其 GH200 超级芯片所做的事情相去不远。「它基本上是一个增压的 Grace-Hopper,没有所有的成本开销,而且效率更高。」
效率提高多少?「我们的内存事务能量开销约为每比特 6.2 皮焦耳,而通过 NVLink、NVSwitch 进行远程内存事务的开销约为 62.5 皮焦耳,」Lazovsky 称,并补充说延迟也不高。
「这些远程内存事务的总往返延迟,包括通过光子结构的两次旅行和内存读取时间,为 120 纳秒,」他补充道:「因此,它将比大约 80 纳秒的本地内存多一点,但它比去 Grace 并读取参数并将其拉到 Hopper 要快。」
据我们了解,这些内存模块中的 16 个可以啮合并为一个内存交换机,并且可以使用光纤随机播放连接多个这些设备。
这意味着,除了计算、存储和管理网络之外,使用 Celestial 互连构建的芯片不仅能够相互连接,而且能够共享内存池。
「这允许你以一种非常非常有效的方式进行机器学习操作,例如广播和减少,而无需切换,」Lazovsky 说。
Celestial 面临的挑战是时机。Lazovsky 告诉我们,他预计将在 2025 年下半年的某个时候开始向客户提供光子织物小芯片的样品。然后,他预计至少还需要一年时间,我们才能看到使用该设计的产品投放市场,并在 2027 年实现销量增长。
然而,Celestial 并不是唯一一家追求硅光子学的初创公司。另一家获得英特尔投资支持的光子学初创公司 Ayar Labs 已经将其光子学互连集成到原型加速器中。
然后是 Lightmatter,它在去年 12 月获得了 1.55 亿美元的 C 轮融资,并试图通过其 Passage 中介层做一些与 Celestial 非常相似的事情。当时,Lightmatter 首席执行官尼克·哈里斯(Nick Harris)声称,它有客户使用 Passage 来「扩展到 300,000 台节点的超级计算机」。当然,和拉佐夫斯基一样,哈里斯也不会告诉我们它的客户是谁。
还有 Eliyan,它正试图通过其 NuLink PHY 完全摆脱中介层——或者如果你必须拥有它们,可以提高中介层的性能和规模。
无论谁在这场竞赛中脱颖而出,向共封装光学器件和硅光子中介层的转变似乎只是时间问题。



评论