

1.简介
MIPS科技是知名的致力于开发和授权高性能处理器内核以及32位和64位架构的公司。作为数字家庭和网络领域中的市场领先者,MIPS架构亦已在32位微控制器(MCU)领域大量应用,与基于ARM架构的内核产品相比,可提供性能更高、功能更丰富且功耗更低的解决方案。
MCU广泛应用于各种市场应用,包括以工业、自动化、汽车、消费电子以及以无线通信为代表的前沿技术。在这些类型的应用中,MCU的运用使得对嵌入式处理器内核的需求不断增长,同时要求嵌入式处理器内核提供更高效的性能、更快的实时响应、更低的功耗以及广泛的生态系统支持。这些需求来源于各种新挑战,包括需要运行更复杂的RTOS控制软件,以及集成更高速的通信接口与更复杂的接口。
32位MCU正逐步为下一代应用提供解决方案。Semico Research Corp.预测32位MCU产品出货量的年复合增长率(compound annual growth rate,CAGR)在未来几年为18%,在2014年出货量将达到25.73亿件。
选择正确的处理器架构是使MCU产品达到性能、成本和上市时间目标的关键决策条件。本文将对MIPS®处理器内核中实现的设计功能进行介绍,这些功能对其达到业界领先的性能起到了关键作用。此外,我们将对基于MIPS和ARM架构(两种最流行的嵌入式处理器架构)的MCU设计解决方案进行比较。我们的分析将会证明,MIPS提供的解决方案性能更高、功耗更低且具有更先进的功能和卓越的开发支持。
2.MIPS架构
MIPS架构于20世纪80年代早期在斯坦福大学诞生,是基于简洁的加载/存储RISC(精简指令集计算)技术的架构。RISC技术实现了简单但全面的指令集,并使用深度指令流水线,与以前的CISC(复杂指令集计算)架构相比,可获得更快的执行速度和更高的性能。相比较而言,ARM架构基于混合的RISC/CISC架构,其设计复杂,且实现高级别性能的能力有限。
自1985年第一块MIPS处理器(R2000)问世以来,MIPS架构始终在不断地完善。指令集架构(Instruction Set Architecture,ISA)在经过几次修订后得到扩展,其性能也相应提高。目前版本包括32位和64位的MIPS32Ò和MIPS64Ò架构。除了基于MIPS32开发一系列32位处理器内核之外,MIPS还对MIPS32和MIPS64架构进行授权。这些架构的授权用户包括Broadcom、Cavium Networks、LSI Logic、NetLogic Microsystems、Renesas Electronics、Sony、Toshiba、中科院计算所和北京君正等,它们正积极地推出适用于数字家庭、网络、单片机和其他应用的MIPS-Basedä产品。这些基于MIPS的产品合计年出货量超过6亿件。

图1:MIPS科技架构和ASE
图1显示了市面上MIPS架构系列的组成部分。标准MIPS32/64架构可通过可选的特定应用扩展(Application Specific Extension,ASE)来扩充功能,包括MIPS16e®、SmartMIPS®、DSP、3D和多线程。这些ASE旨在分别针对特定应用提供增强功能。例如,DSP ASE通过增强软硬件功能,加速了MIPS处理器内核设计中的信号处理功能。类似地,MIPS16e是将“最经常”使用的MIPS32指令解码为相应的16位等效指令后所组成的指令集。与MIPS32相比,MIPS16e可压缩应用程序代码,使其占用较少的存储器容量,同时通过减少存储器带宽和缩短执行时间来保持高性能。图1中所示的每种ASE均有助于提高目标处理器内核的特定于应用的性能。
MIPS科技最近推出的microMIPS™是一套完整独立的指令集架构(ISA),同时包含16位和32位指令,旨在使软件代码密度和执行吞吐量最大化。microMIPS可至少将代码长度减少30%,并且执行性能几乎与MIPS32相同。microMIPS 集成于MIPS32 M14K™和M14Kc™处理器内核中,这些内核是为MCU和嵌入式控制器SoC的设计而开发的。
通过MIPS32/64架构中实现的先进技术及其处理器内核中包含的先进功能,MIPS ISA标准软件平台超越了竞争对手的解决方案并提供了更大的灵活性和持续改进的空间。
2.1 MIPS架构性能
从高端多核解决方案到紧凑型内核,所有MIPS处理器内核均基于相同的高性能MIPS32基础架构进行设计。
MIPS内核的主要性能改进来自于内核执行单元的功能增强,通过实现较长的流水线级数、超标量和多线程微架构来提高处理器的最大工作时钟频率。通过在标准架构中加入高速存储器接口、高效缓存控制器、存储器管理单元、大量寄存器组以及浮点加速器等设计功能来获得附加性能。
MIPS32架构标配32个通用寄存器(General Purpose Register,GPR),其中每个寄存器的位宽为32位。在芯片设计阶段可以对MIPS配置更多的通用寄存器组(每组32个),用作附加数据存储或者分配给专用向量中断控制器逻辑的“影子寄存器”,在传统软硬件方法的基础上可显著减少中断延时和现场切换时间。
利用硬件乘除单元(Multiply Divide Unit,MDU)以及多个带符号/无符号乘法、除法和乘加(MAC)指令的软件支持,可有效提高MIPS32架构的信号处理性能。MIPS架构对MDU采用独立的流水线,使其可以与整数流水线并行工作。
2.2 比较MIPS与ARM的性能特点
以RISC技术为基础,并与可扩展的硬件和软件设计相结合,MIPS架构比ARM架构提供了更高性能、更低功耗和更为紧凑的设计。MIPS起源于高性能工作站和服务器的设计,而ARM的初衷是针对低端移动系统开发的基本内核。MIPS以其高性能产品的开发经验和设计优势进入主流嵌入式系统市场。而ARM传统架构中延续的种种方面限制其所能达到的性能等级,这使其与MIPS相比处于不利地位。
MIPS32 4K®处理器内核(包括MIPS32 M4K®内核)比同级的ARM Cortex-M系列内核的性能更加优良,应用程序的运行速度更快。一部分原因是采用了更高效的MIPS ISA和经过优化的软件工具,但主要原因是MIPS架构优越的设计功能,可实现更高的性能和执行效率,包括对单片机设计中实现的典型功能进行加速。例如:
MIPS内核包含32个GPR,而ARM内核只包含16个GPR。这减少了寄存器溢出,从而实现更高的性能。
MIPS内核包含影子寄存器组,而ARM内核不包含。使用影子寄存器可以加速中断处理的保存/恢复功能,从而使现场切换和中断延时占用更少的周期。
MIPS架构主要执行单操作指令,而ARM指令在写入GPR之前执行多次操作(例如,移位操作数、运算、检查条件位以及其他操作)。这使得MIPS可以更容易地达到较高的时钟频率。
与ARM相比,MIPS架构工作时采用的存储器寻址模式更简单,从而更容易达到较高的时钟工作频率。
MIPS架构的预测执行较少,这最大程度地降低了逻辑复杂性,并使MIPS内核可达到较高的频率。
M4K和M14K无需分支预测。而ARM内核采用复杂的分支预测逻辑。
MIPS架构实现了带延迟的分支,而ARM架构未实现,因此在短流水线设计时MIPS可实现更高的效率。
MIPS同时提供32位和64位架构,均可向下兼容并且更高性能的MIPS64也提供向下兼容。而ARM只提供32位架构,并且不是所有版本都支持向下兼容。
3.专为高性能MCU设计的处理器内核
在2002年,MIPS科技推出了M4K内核,这是一款高性能的综合性处理器内核,专为MCU和小尺寸嵌入式控制器设计而进行了优化。作为4K系列内核(已拥有超过120家被授权商)的成员之一,M4K已授权于近30家公司,其作为控制器而被广泛应用于移动手机、DTV、电缆调制解调器、GPS和数码相机系统中。此外,M4K内核在Microchip Technology的32位PIC32系列MCU产品中作为标准微控制器实现。
M4K内核的一系列设计功能提供了一流的性能,明显优于ARM Cortex-M系列处理器。
3.1 M4K执行流水线
M4K内核的性能可达到1.5 DMIPS/MHz,而按照ARM网站所列,Cortex-M3的性能只能达到1.25 DMIPS/MHz,大约比M4K低20%。(ARM Cortex-M0的性能甚至低至0.9 DMIPS/MHz,比MIPS32 M4K内核低40%。Cortex-M0还具有众多其他限制,我们将在后文介绍。)换句话说,Cortex-M3需要将时钟频率提高20%才能达到与M4K内核相同的性能,但这样做的后果是产生额外的功耗。
类似地,如第4节所述,M4K内核运行CoreMark基准测试的结果是2.297 CM/MHz,比同级的基于Cortex-M3的解决方案高出20-30%。MIPS注意到越来越多的人接受了CoreMark基准测试,因为与Dhrystone DMIPS相比,其对于CPU性能的测量更精确。
M4K的执行单元采用5级流水线微架构(如图2所示),而Cortex-M3内核的执行建立在3级流水线架构上。M4K内核的更深层流水线使其可工作于更高的最大时钟频率,这样每秒可处理更多指令,从而实现比Cortex-M3更高的性能和执行效率。
在M4K内核中,所有ALU和移位运算都在单个周期内完成。流水线中含有旁路逻辑,可提供对数据的快速访问,让数据在流水线执行完成前供下一个指令调用。这使得执行特定任务所需的周期数减少,因而性能得以提高。
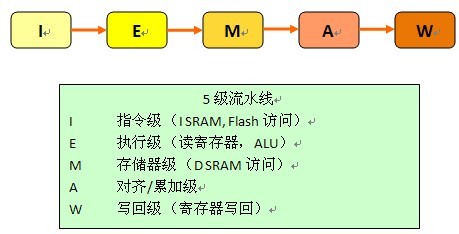
图2:M4K内核5级流水线
3.2 系统协处理器(CP0)
系统协处理器(CP0)是MIPS架构所特有的,可以在M4K内核中找到。CP0作为辅助执行单元工作,可减少内核资源的某些管理操作(包括异常处理和存储器管理),从而提高内核性能。
3.3 通用寄存器(GPR)和影子寄存器
M4K内核提供一个配置选项,可将GPR的数量增加到最多16组,且每组都有完整的32个寄存器。这些GPR可在片上存储参数和操作数,从而减少存储器转移开销并减少指令周期。这对增加计算吞吐量有着积极作用。
如前文所述,使用GPR作为影子寄存器可以减少服务中断(MCU系统中的常见事件)所产生的开销,从而提高系统性能。
当处理中断或异常时,M4K内核会决定使用哪个影子寄存器组并使其成为激活的GPR组,以允许中断向量继续执行。此过程完全不需要现场保护或恢复周期,因为指定的中断服务程序是当前激活的影子寄存器的唯一所有者。这意味着不仅在中断或异常代码实际开始执行前不会浪费时间,而且自上一次异常或中断事件激活以来的寄存器内容都会被保留。这会节省从SRAM空间重新获取特定值的时间。
3.4 MDU
M4K内核中的高性能MDU可在一个周期内完成一次32x16位乘法(或MAC指令)。在两个周期内完成32x32位乘法/MAC运算。
MDU有自己的专用功能单元,可独立于内核执行流水线进行工作。任何乘法/除法指令都会被送到MDU,这样内核流水线可并行处理其他操作,例如需要ALU、加载/存储和移位运算的指令。M4K内核中的MDU具有使信号处理运算加速的优势,例如FFT、FIR和IIR这些在工业和网络型应用中通常由单片机执行的滤波计算。以M4K加速DSP型函数的能力为例,PIC32在80MHz的频率下运行256点的16位radix-4 FFT运算需要22K个周期,共花费283ms,比基于Cortex-M3的单片机STM32少用14%的周期。
3.5 SRAM接口
访问代码和数据的速度快慢对处理器性能有明显影响。设计人员致力于设计一种存储器接口,使可用带宽最大化且最大程度地降低延迟,目标是实现0等待状态的数据传送。MIPS架构采用灵活的存储器总线结构,允许从高速闪存或高性能片上SRAM中执行代码。M4K内核集成了一个用于指令和数据存储器的高速、低延时SRAM接口。该接口支持单周期和多周期存储器访问。M4K SRAM接口可工作在双模式或统一模式下。双模式提供最高的性能,并具有控制数据(D-SRAM)和指令(I-SRAM)的独立总线。双模式允许在I-SRAM和D-SRAM接口上同时执行数据传输,以消除公用总线接口上可能产生的冲突现象。
I-SRAM接口能够重新定向信号输入,必要时允许将D-SRAM读周期重新定向到I侧。这样便可实现改良的哈佛架构(这是基于MCU的系统的常规特性),允许将非易失性数据存储在程序存储器中。
SRAM接口可在M4K内核的5级流水线中的任意位置中止指令事务。这样便可从外部系统控制器对外部事件(例如中断请求或通过EJTAG调试接口发出的请求)做出立即响应。在处理典型单片机应用的高决定性操作时,对外部中断事件的快速响应至关重要。
SRAM接口还可中止延时较长的数据传输。在处理典型单片机应用的高决定性操作时,对外部中断事件的快速响应至关重要。
M4K内核中的SRAM接口是一个高速、易用且可灵活配置的存储器接口,其中大多数传输可在一个时钟周期内完成。它除处理指令和数据存储器之外不会产生任何额外的协议或信号开销,这使芯片设计人员可充分利用M4K内核的最大性能。
Cortex-M3则没有如此全面的存储器控制功能,因此在性能上不如M4K内核。
3.6 CorExtend™
CorExtend是MIPS32架构的另一个独特功能,它为开发人员提供了产品差异化和定制功能。它是一个配置选项,通过用户定义指令(User Defined Instructions,UDI)与定制硬件的结合来扩展内核指令集。设计人员可通过CorExtend为内核增加功能,在目标应用中对成为瓶颈的特定应用功能进行加速,从而提高系统的整体性能。在典型MCU环境中,CorExtend可用于设计专用图形控制器、TCP/IP加速器、定制安全/加密逻辑、无线基带控制或其他实时控制接口等。CorExtend与内核流水线协同工作,如图3所示。CorExtend的功能与MIPS32完全兼容,并且所有领先的MIPS兼容开发工具均能支持。

图3:CorExtend流水线结构
4.性能基准测试
CoreMark是EEMBC开发的开源基准测试工具,专为测试处理器内核的性能而设计。CoreMark的架构可将处理器内核与任何相关系统隔离,包括存储器子系统的影响以及编译器可能使出的“优化把戏”。CoreMark可测试处理器流水线以及常用功能(包括读/写、整数和控制操作)的性能。因此,它提供的测试结果中的人为影响要比其他基准测试少,更接近处理器内核的真实性能。
源自CoreMark网站所述:“测试内容实际由多个常用算法组成,包括矩阵操作(允许使用MAC和常用数学运算)、链表操作(执行指针的常规用途)、状态机操作(数据相关分支的常规用途)以及循环冗余校验(CRC是嵌入式应用中很常用的功能)”。
图4比较了一些基于MIPS M4K和ARM Cortex-M3及M0的MCU的数据,这些数据取自CoreMark公开网站。
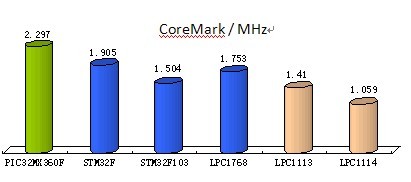
图4:M4K PIC32与ST和NXP Cortex-M器件的CoreMark比较结果
工作在80MHz下的M4K PIC32采用2等待状态的存储器,其性能优于竞争对手的采用0等待状态存储器的Cortex-M3和M0器件,具体数据为:
比工作在120MHz下的STM32F高20%
比工作在72MHz下的STM32F高50%
比工作在100MHz下的LPC1768高31%
比工作在50MHz下的LPC1113高63%
5.低功耗与紧凑设计
典型SoC的大部分功耗和面积来自于处理器内核外部的存储器、外设和控制逻辑。然而MIPS科技明白,在单片机设计中,除了最佳的性能效率外,芯片成本和功耗也是产品取得成功的关键因素。MIPS在处理器内核设计中加入了特定功能,以最大程度地减少面积和功耗,本节将介绍其中一些功能。MIPS科技通过提供最佳的面积和功耗解决方案巩固了其在性能上的领先地位,具体内容将通过以下几节中M4K与Cortex-M3的比较结果为您展示。
5.1 低功耗特性
M4K微架构的高性能允许应用工作于比其他内核更低的时钟频率。功耗与频率成正比,因此降低频率就是降低功耗。如前文所述,M4K内核的处理性能至少比Cortex-M3高20%,即功率效率(DMIPS/mw)更为出色,这意味着完成同一项作业需要的功耗更低。M4K内核的高性能有助于降低功耗,因为它可以更快地完成任务,从而有更多时间处于低功耗(空闲)状态下。
M4K内核是可综合设计,在不同低功耗工艺和物理库之间可任意移植。该内核是静态设计,允许时钟实时变化(需要时降至较低频率)。它甚至支持时钟停止,这会将功耗降至最低的uW级别(这种情况下的功耗主要取决于工艺上的漏电流)。
M4K内核提供多种功耗管理功能,通过使用微调时钟门控来控制动态功耗并支持掉电模式。M4K内核的大部分功耗来自于时钟逻辑和寄存器。在整个M4K内核中大量采用时钟门控,这可以提供一种有效的机制,即对于内核中的选定区域,当不使用时可将其关闭。M4K内核还提供一种机制,即使用内部寄存器通过特定WAIT指令控制内核进入低功耗和休眠模式。当执行WAIT指令时,内部时钟暂停,流水线冻结。任何中断或复位都将使内核退出休眠模式并恢复正常工作。
这些有效的功耗管理功能,连同低功耗设计工具的支持,都有助于显著降低动态功耗。与来自ARM网站的数据相比,在相似的配置和频率下,我们发现在采用180 nm制程时,M4K内核与Cortex-M3的动态功耗(mW/MHz)相似。
但采用90 nm制程时,工作在50 MHz且经面积优化的Cortex-M3的功耗为0.10 mW/MHz,额定功效为12.5(DMIPS/mW)。在相同的90 nm节点以及更高的200 MHz时钟频率和经面积优化的配置下,M4K的功耗仅为0.04 mW/MHz:与Cortex-M3相比,功耗降低60%,而功效是其2倍。
M4K内核在130 nm制程时显示出相似的低功耗特性。由于没有Cortex-M3在130 nm制程下的数据可供比较,因此下面我们只给出M4K在130 nm制程下的功耗数据:
在最大频率216 MHz以及经速度优化的配置下,功耗为0.17 mW/MHz
在100 MHz频率以及经面积优化的配置下,功耗为0.06 mW/MHz
5.2 小尺寸特性
M4K内核是高效、高度可配置且灵活的处理器内核。图5显示了M4K内核中的可选模块,包括调试/跟踪(ETAG)、CP2协处理器接口和CorExtend扩展。MIPS16e ASE指令解码器是可选的。
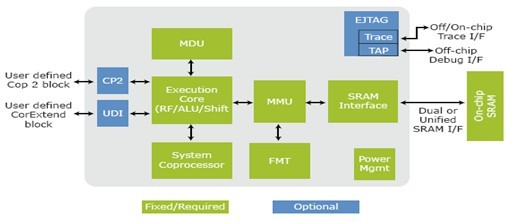
图5:M4K内核框图
为减少门数规模,M4K内核提供了一组全面的配置选项。可配置选项包括使能/禁止调试功能、设置调试/跟踪断点的数量和类型、快速或慢速MDU、设置GPR寄存器的数量以及统一或合并数据和地址SRAM接口统一或分离。
这些配置选项综合用于实现速度或面积优化,以满足所需的应用目标频率,同时生成最小尺寸和最低门数。内核面积取决于工艺、单元库和目标性能。要对M4K与Cortex-M3在内核面积方面进行有意义的比较,应该考虑到这些因素。不过M4K内核的门数可低至33K,那么即便不考虑其功能多于Cortex-M3,M4K内核的尺寸仍比Cortex-M3小。
6.生态系统
SoC开发环境(包括硬件/软件调试工具和其他第三方解决方案)是处理器选型中的重要考虑因素。
MIPS科技拥有一个专门团队,提供一系列硬件和软件开发工具,帮助设计人员在SoC中成功集成和测试MIPS处理器内核,并在目标系统应用中验证其工作情况。这些工具包括System Navigator™ EJTAG仿真器、支持RTOS和Linux系统的GNU软件工具链、用于软件评估和协同模拟的周期精确与指令精确的模拟器、基于FPGA的开发/评估板和Navigator集成开发环境元件套件(ICS),以及基于Eclipse且与其他MIPS工具完全整合的开发环境。

图6:System Navigator调试探针和SEAD3开发板
此外,MIPS科技还建立了MIPS联盟计划(MAP),以支持其广泛的第三方生态系统。MAP是一个由100多个合作伙伴组成的群体,提供了数百种支持MIPS架构和处理器内核的解决方案。对于那些想通过MIPS兼容工具缩短上市时间的设计人员以及以各种市场应用(包括MCU)为目标的解决方案来说,该生态系统是一个很好的资源。
MIPS生态系统已发展成为一个丰富且多元化的基础结构支持,包括合作伙伴提供的OS、RTOS、硬件调试工具、软件开发产品、应用软件、EDA工具、物理IP和其他特定应用的相关产品。对于MCU开发,可从多家厂商获得生态系统的支持示例。以下是一些提供MCU支持的MIPS联盟合作伙伴:
RTOS厂商,例如Express Logic、Mentor Graphics、Micrium、Segger、Green Hills Software、Wind River、CMX和FreeRTOS
提供调试探针和仿真器的厂商,例如:Ashling、Lauterbach、Macraigor和Corelis
提供软件开发工具的厂商,例如:CodeSourcery、Green Hills、Mentor Graphics和Hi-Tech
提供模拟模型的厂商,例如:Carbon和Imperas
提供SoC IP的厂商,例如:Sonics、Dolphin和Denali
提供EDA/ESL工具的厂商,例如:Synopsys、Cadence和Magma
7.MIPS32 M14K 内核
MIPS科技最近推出了两款属于MIPS32 4K内核系列的新处理器内核,继续在单片机以及其他高性能、紧凑尺寸和成本敏感型嵌入式应用方面不断创新。MIPS32 M14K与M14Kc内核采用双解码器设计,包含MIPS32和microMIPS指令解码器。这两个内核是首批采用microMIPS指令集的MIPS32兼容内核。microMIPS可以使性能等级在高代码密度下不打折扣:至少减少30%的代码长度,同时保持MIPS32的性能。
M14K内核的设计采用与M4K内核相同的高性能5级流水线架构。M14K处理器内核是M4K内核的超集,它在保留M4K内核的所有功能的同时还增加了用于减少中断延时、加速访问闪存代码以及增强中断处理能力的功能。此外,M14K内核还提供一组全面的高级调试/评估功能和一个标准AHB接口。

图7:M14K内核框图
M14K内核具有M4K内核相对于Cortex-M3的所有优势:更高的性能、更低的功耗、更小的尺寸以及更高的可配置性和灵活性。此外,M14K内核还有更多方面优于Cortex-M系列,详细内容如表1所示。
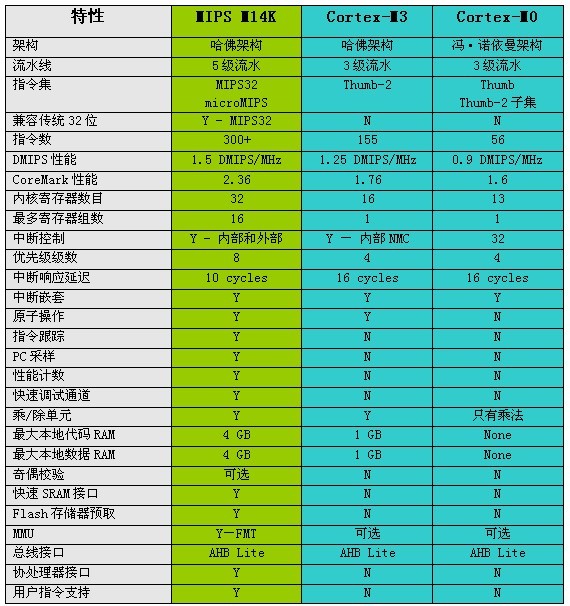
表1:M14K、Cortex–M3和Cortex-M0的功能比较
Cortex-M0简介:Cortex-M0采用ARMv6M版的架构,。它实质上是加入了一些Cortex-M3功能的ARM7,采用3级流水线,性能为0.9 DMIPS/MHz,低于Cortex-M3的性能。
Cortex-M0可执行总共56条Thumb和Thumb-2指令,其中仅有6条为32位指令。大多数针对Cortex-M3编写的代码,必须经过修改才能在Cortex-M0上运行。
Cortex-M0与ARM7一样,重新采用了冯诺伊曼架构。Cortex-M0不支持局部存储器,而是通过AHB总线从主存储器访问代码和数据,这会明显降低性能,因为在数据传送完成前需要额外的等待状态。
完整的Cortex-M0大小大约为24K门。尽管尺寸很小,但缺少许多M4K或M14K内核(经面积优化配置,约33K门)所具有的标配功能和性能。Cortex-M0在性能和功能上的损失与节省的面积相比并不划算。
8.结论
MIPS科技是公认的为数字家庭和网络市场领域提供高性能和高效应用产品的供应商。针对单片机设计人员所面临的技术挑战,特别增强了标准MIPS架构的功能,并提供优于ARM Cortex-M系列产品特性,如更出众的性能、更低的功耗以及更高级的功能。
M4K和M14K内核的效率和可配置性为MCU和嵌入式控制器的设计人员提供了“以一替三”的方案:M4K/M14K内核具有比Cortex-M3、M0或M1更强大的性能和功能,可替代任何一款内核使用。
当今越来越多的MCU应用需要具备高性能、低功耗和实时响应的特性,因而采用32位处理器架构是最佳选择。
下面的总结有助你透过广告看事实,并且提供选择MIPS处理器内核时应考虑的关键因素:
性能
MIPS M4K和M14K内核采用5级流水线架构,性能达到1.5 DMIPS/MHz。ARM Cortex-M3和M0为3级流水线设计,性能分别为1.25和0.9 DMIPS/MHz,比M4K/M14K的性能低20%和60%。
在180和90 nm制程下,M4K和M14K内核可达到的最大时钟频率比同等配置的Cortex-M3内核高20%。
即使在时钟频率降低33%(80MHz对比120MHz)并使用慢速存储器(2等待状态闪存对比0等待状态闪存)的情况下,MIPS M4K PIC32器件的CoreMark性能测试结果仍比ARM Cortex-M3 STM32高20%(2.297对比1.905)。
在同等时钟频率下,在代码访问时仍然使用2等待状态的PIC32器件CoreMark性能测试结果比STM32F高50%。
M14K中断延时为10个周期,而Cortex-M3为12个周期。M14K内核处理背对背中断所需的周期数比Cortex-M3少30%。
PIC32和M14K内核采用预取缓冲区来减少访问闪存存储器的时间,并采用快速SRAM接口实现比Cortex-M3更快的执行时间。
在执行常用信号处理如FFT算法时,PIC32的DSP性能比STM32(Cortex-M3)高14%。
低功耗
在90 nm制程下,M4K内核的功耗比Cortex-M3低60%,而性能是Cortex-M3的3倍。同样在90 nm制程下,M14K内核的功耗比Cortex-M3低70%,而性能是Cortex-M3的2倍。
MIPS生态系统:MIPS及其合作伙伴提供了广泛的服务,其中包括提供硬件和软件开发工具、兼容领先的RTOS系统、中间件和支持领先的EDA工具,这些均有助于设计人员减少开发时间并加快上市时间。
成熟的技术,更低的风险:MPS32和MIPS64架构已成功应用到数十亿个SoC中,涉及范围广泛的各类应用。MIPS是数字家庭(DTV和STB)、宽带接入以及无线网络(WLAN和WiMAX)和便携式多媒体(数码相机、游戏机和导航)领域的市场领先者。
随着行业日益从8位/16位MCU架构向32位架构迁移以跟上不断增长的性能需求,MIPS科技在高性能和能效方面的领先优势将非常适合于驱动下一代产品的开发。
参考信息
MIPS 科技 www.mips.com
ARM www.arm.com
EEMBC CoreMark www.coremark.org
Microprocessor Report www.mdronline.com
Berkeley Design Technology Inc www.BDTI.com
“See MIPS Run”,Dominic Sweetman著,ISBN 13:978-0120884216
“Exploring the PIC32”,Lucio Di Jasio著,ISBN 13:978-0750687096
 STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂