
使用新SRAM工艺实现嵌入式ASIC和SoC的存储器设计
基于传统六晶体管(6T)存储单元的静态RAM存储器块一直是许多嵌入式设计中使用ASIC/SoC实现的开发人员所采用的利器,因为这种存储器结构非常适合主流的CMOS工艺流程,不需要增添任何额外的工艺步骤。
本文引用地址:http://www.amcfsurvey.com/article/149644.htm如图1a中所示的那样,基本交织耦合锁存器和有源负载单元组成了6T存储单元,这种单元可以用于容量从数位到几兆位的存储器阵列。
经过精心设计的这种存储器阵列可以满足许多不同的性能要求,具体要求取决于设计师是否选用针对高性能或低功率优化过的CMOS工艺。高性能工艺生产的SRAM块的存取时间在130nm工艺时可以轻松低于5ns,而低功率工艺生产的存储器块的存取时间一般要大于10ns。
存储单元的静态特性使所需的辅助电路很少,只需要地址译码和使能信号就可以设计出解码器、检测电路和时序电路。
随着一代代更先进工艺节点的发展,器件的特征尺寸越来越小,使用传统六晶体管存储单元制造的静态RAM可以提供越来越短的存取时间和越来越小的单元尺寸,但漏电流和对软故障的敏感性却呈上升趋势,设计师必须增加额外电路来减小漏电流,并提供故障检测和纠正机制来“擦除”存储器的软故障。
当前6T SoC RAM单元的局限性
然而,用来组成锁存器和高性能负载的六晶体管导致6T单元尺寸很大,从而极大地限制了可在存储器阵列中实现的存储容量。
这种限制的主因是存储器块消耗的面积以及由于用于实现芯片设计的技术工艺节点(130,90,65nm)导致的单元漏电。随着存储器阵列的总面积占整个芯片面积的比率增加,芯片尺寸和成本也越来越大。
漏电流也可能超过整个功率预算或限制6T单元在便携式设备中的应用。更大面积或高漏电芯片最终可能无法满足应用的目标价格要求,因此无法成为一个经济的解决方案。
作为6T RAM单元替代技术的1T单元
对那些要求大容量片上存储(通常大于256kb)但不要求绝对最快存取时间的应用来说还有另外一种解决方案技术。这种解决方案所用的存储器阵列功能类似SRAM,但基于的是类似动态RAM中使用的单晶体管/单电容(1T)存储器单元(图1b)。
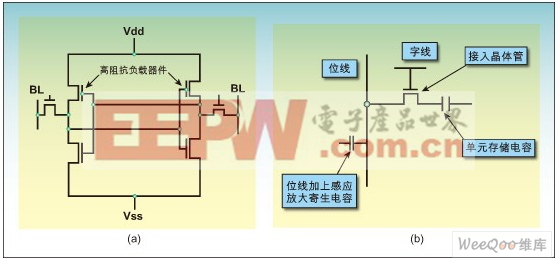
图1a:典型的六晶体管静态RAM存储单元。图1b:典型的单晶体管/单电容动态存储器存储单元。
这种存储器阵列在相同芯片面积上的密度可以达到6T存储器阵列的2到3倍。当嵌入式存储器要求超过几兆位时可以使用简单的动态RAM阵列,但这种阵列要求系统控制器和逻辑理解存储器的动态特性,并正确地提供刷新控制和时序信号。
嵌入简单DRAM存储器块的另外一种方法是将DRAM阵列和它自身的控制器捆绑在一起,使它看起来像是易于使用的SRAM阵列。通过整合高密度1T存储单元和提供刷新信号的一些支持逻辑,存储单元的动态特性对ASIC/SoC设计师来说是看不见的,设计师在实现ASIC和SoC解决方案时可以将它们当作静态RAM使用(图2)。
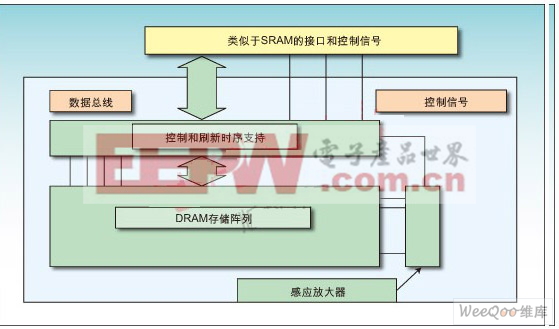
图2:DRAM存储器阵列周围增加的控制和接口支持逻辑使得该阵列用起来像静态RAM,因此可以提高存储器密度。
一些公司和代工厂已经开发的1T单元除了标准CMOS层外还需要额外的掩模层。因此这种方法增加了晶圆成本,并且与具体的代工厂密切相关,只能将制造过程限制于特定的代工厂。为了弥合额外的晶圆处理成本,芯片中使用的总的DRAM阵列尺寸一般必须超过裸片面积的一半以上。另外,大部分DRAM宏是尺寸、长宽比和接口都受限的硬宏。
SoC设计则需要更具性价比的IP宏,根据成本或容量的需要,这些IP宏可以方便地在任何代工厂中制造,或者从一个代工厂转移到另一个代工厂。在版图和配置阶段,这种宏还能向ASIC设计师提供更多的灵活性。
多家代工厂拥有这种所谓的“单晶体管SRAM”技术,并作为可授权的知识产权。这样一种以编译器为主导的方法已见用于bulk CMOS工艺中,由于没有额外的掩模步骤,因此可以降低15-20%的晶圆成本,并可缩短产品上市时间。
对于系统的其它部分来说,上述方法形成的存储块接口看起来就像是一个静态RAM,但与采用6T单元的存储器阵列相比,它的密度(单位面积的位数)可以达到后者的2到3倍(在将作为面积计算一部分的支持电路开销进行平均后)。存储器阵列越大,支持电路需要的总面积就越小,存储块就有更高的面积效率。
为了创建理想的存储器阵列,可以使用像MemQuest这样的存储器编译器工具。这些工具允许设计师实现更冷、更快或更高密度的coolSRAM-1T配置,这些配置可以在不同的代工厂和技术节点间移植(见图3),从而可以避免人工阵列实现所需的非重复性工程费用。
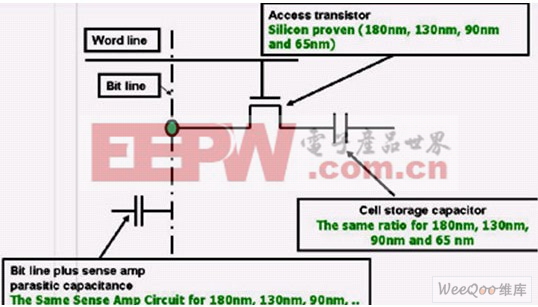
图3:便携式coolSRAM-1T设计用于特别低功率的设备,它通过自适应电路尺寸调整、虚拟接地、自适应后向偏置和其它电路技术来降低漏电流。
编译器还可以帮助用户使用最优的内核尺寸、接口和长宽比并实现最短的上市时间,并向设计师提供它编译的存储器阵列的电气、物理、仿真(Verilog和VHDL)、测试和综合结果。
在一个1Mb的存储器阵列实例中,例如coolSRAM-1T配置,存在着室温下为数微安的漏电流,对于供电电压和时钟速率来说这是一个典型的边界条件(图3)。
在采用100kHz或100kHz以下的典型刷新速率以及128k字×8位的组织结构时,1Mb coolSRAM-1T阵列有一个空闲功率能使数据保持时间与同样容量的SRAM相当。(coolSRAM-6T的1Mb实例在采用台积电公司的130nm G工艺制造时将占用约2.6平方毫米的面积,每兆赫兹消耗功率小于100微瓦)
虽然SRAM-1T功能如同SRAM,但内部却具有DRAM的特征-当采用130nm工艺实现时,室温下的存储单元可以保持数据数十毫秒的时间。支持的刷新控制逻辑透明地提供刷新功能,并能根据温度调节刷新周期。
如果设计师想用SoC管理刷新,也可以选择旁路掉存储器阵列中的刷新控制器,使用来自SoC逻辑的刷新信号。这样可以有效地节省SoC中的一些动态功耗,因为系统逻辑可以“按需”而不是“自动”实现SRAM-1T的嵌入式刷新逻辑。
SRAM-1T实例中的存储单元也支持睡眠和待机模式。在睡眠模式时,可以通过抑制大部分存储器阵列的时钟来极大地降低功耗。
当阵列“被唤醒时”,数据必须被重新装载进存储单元。在待机模式时,存储器通过使用低频刷新操作使数据得以保持,此时功耗是很小的。当返回到工作模式时,存储器可以立即投入使用,数据不需要重新被装载进存储器阵列。
设计师还能通过配置让存储器阵列以不同的行尺寸-256、512、1024或2048位进行刷新,甚至实现多行同时刷新。还允许设计师有选择的只刷新阵列的一小部分以保持关键数据不丢失,同时切断阵列其余部分的供电。
对任何存储器阵列来说,制造工艺的变化总是有可能导致存储器阵列中出现一二个坏的位。这样的芯片不一定要废弃,设计师只需增加列和行冗余机制就能提高良品率。
如果芯片交付后发生位故障,可以采用内置自修复功能以及一次性可编程coolOTP存储器修复存储器阵列。另外,内置自检功能也可以增加进存储器IP块中,它不会影响芯片的性能。
当存储器阵列的基本性能不能满足系统需要时,设计师可以使用一些结构化技术从存储器阵列中获得更高的性能。然而,使用这些技术需要付出一定的代价,它们会影响芯片的功耗、尺寸和复杂性,因此必须认真地进行权衡分析,确定最佳的存储器阵列和芯片架构组合,这样才能实现理想的性能和成本目标。
对芯片架构设计师来说使用宽字架构是一种不错的选择,它能将存储器组织成在内部提供128、256或1024位宽数据字,然后向下复用成想要的字宽度(见图4)。
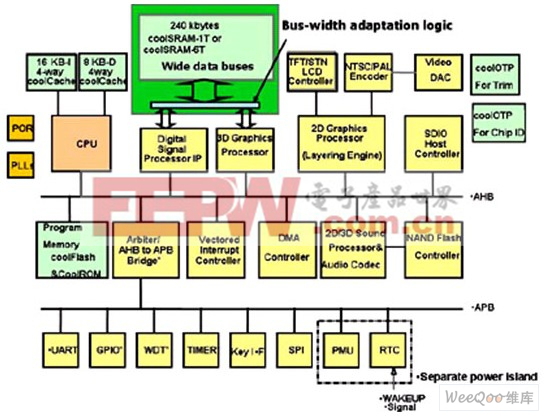
图4:在典型的SoC设计中,宽的内部存储器总线可以用来快速传送图形和DSP处理中的实时性数据。
这种技术可以将视在时钟速率(apparent clock rate)提高2倍或4倍,从而减少实际存取时间,最终降低功耗。在这种情况下,由于需要解复用逻辑将宽字减小到适合SoC其余部分使用的合适宽度字,会对IP设计产生面积上的消极影响。
另外一种方法是将存储器划分成多个实例(区),并设置存储器控制器,让它以连续周期交替访问这些实例(instance),这样通过区与区之间的切换就可以隐藏掉某段存取时间(见图5a)。
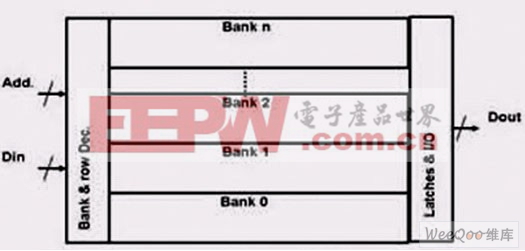
图5a:通过增加一些额外的控制和时序电路可以实现多个存储实例(区)的交叉存取,从而将到主处理器的数据速率提高2倍、3倍甚至4倍(取决于区的数量)。
在非交织存取系统中,存储器子系统必须工作在系统时钟速度,此时如果存储器访问不能同步于时钟,那么整个系统的运行速度就会慢下来(见图5b)。
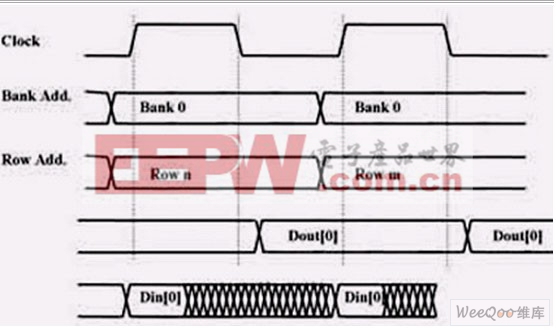
图5b:在非交叉存取系统中,存储器区的访问时间会在访问存储器阵列时限制系统时钟速度。
但在交织存取的存储器系统中,时钟频率可以2倍、3倍、4倍的提升,具体取决于区的数量。但当交织存取超过两个区时,系统复杂性会有相当大的增加。
对于双区系统,时钟频率可以是每个存储区可处理的最大速度的2倍,但由于每个实例是以时钟频率的一半循环的,单个区不能感受到时钟速度的变化(见图5c)。
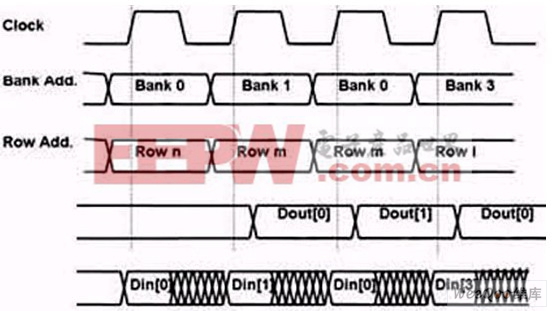
图5c:在交叉存取的多区系统中,时钟速度可以达到非交叉存取时钟速度的数倍(时钟x区数量)。
而且,围绕存储区的一些全局逻辑以双倍于存储器速度运行,并在交替时钟周期中向两个区中的每个区传递地址信息。这种全局逻辑可以在多个区中 共享,从而可以节省面积和功率。
数据输入/输出端口的附加逻辑对数据进行复用或解复用,并向主机系统以双倍数据速率提供数据,或以输入速率的一半向存储区提供数据。因此存储器子系统的有效吞吐量提高了一倍,而有效功率比两倍存储容量的单个块要低。
虽然这种方法可以将存取时间缩短近50%,但也带来了额外的支持电路和设计/时序复杂性。此时对存储器的数据访问一般都要被延迟一个周期(单周期延迟访问),并且访问是准随机性的,系统无法在每个周期访问相同的内部区。(Novelics公司)
linux操作系统文章专题:linux操作系统详解(linux不再难懂)



评论